[Day27] AWS Data Pipeline
AWS Data Pipeline 是一种 Web 服务,可协助您以指定的间隔,可靠地在不同 AWS 运算与储存服务以及内部部署资料来源之间处理和移动资料。使用 AWS Data Pipeline,您可以时常从资料的存放处直接存取、大规模转换和处理这些资料,并将结果有效率地传输到 Amazon S3、Amazon RDS、Amazon DynamoDB 和 Amazon EMR 等 AWS 服务。
AWS Data Pipeline 可协助您轻松地建立容错、可重复且高可用性的复杂资料处理工作负载。您不用担心如何确保资源可用性、管理内部任务相依性、发生暂时性故障或逾时问题时重试个别任务,或建立故障通知系统等事项。AWS Data Pipeline 还可让您移动和处理之前在内部部署独立资料区块中锁定的资料。
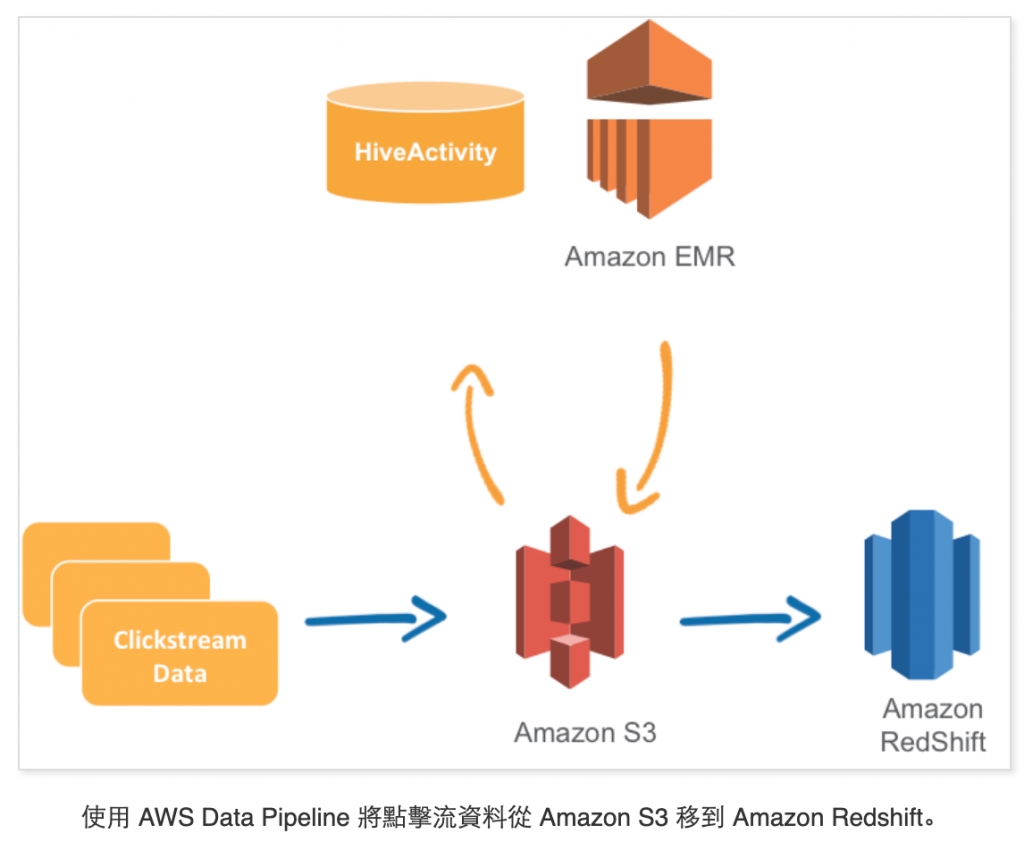
您也可以定义先决条件,检查资料是否可用,再启动特定活动。在上述范例中,您可以在 S3DataNode 设定先决条件,检查日志档是否可用,再启动 HiveActivity。
AWS Data Pipeline 处理:
- 任务的排程、执行和重试逻辑。
- 追踪商业逻辑、资料来源和之前处理步骤之间的相依性,确保满足所有相依性之後才能执行您的逻辑。
- 传送任何必要的失败通知。
- 建立和管理您任务所需的任何运算资源。
Day 3 - 用 canvas 复刻 小画家 画笔
说明 根据 MDN 的教学 一开始canvas为空白,程序码脚本需要先存取渲染环境,在上面绘图,然後...
铁人赛Day28-第八章:恐龙在草地上奔跑吧!
昨天将恐龙转场的部分完成後,我们来将他做个收尾。 1.开启昨天的档案 2.为了後续需要延长秒数 3....
day7 我不要了,这不是肯德基 cancel
Cancellation is important for avoiding doing more ...
Day29 - 【概念篇】用Keycloak学习JWT权杖格式 - JWT权杖格式介绍(1)
本系列文之後也会置於个人网站 在今天文章之前... 小财神,「铁人发文」按钮还在阿! 好拉!那既然...
Day 16 - Array Methods
map() 和 forEach 很像,不同处在於 forEach 没有回传值,使用 map 时会 r...