【26】你都把 Batch Normalization 放在 ReLU 前面还是後面
Batch Normalization 到底要放在激励函数之前还是之後呢?这是之前我在自己练习规划架构时遇到的问题,我把这个问题拿去网路上查时,发现也有不少人在讨论它,这篇 reddit 的讨论 [D] Batch Normalization before or after ReLU? 我觉得蛮有意思的,放前面跟放後面都各自有论文推崇。
理论上 BN 是用来正规化输出的结果,如果今天放在 ReLU 之後,有些负的输出会变成0,那麽 BN 的正规化是不是就会有偏颇?所以我自己也是习惯把 BN 放在激励函数前,先将 CNN/Dense 的输出正规化之後再经过激励函数。
但是也有不少的实验结果得到把 BN 放在激励函数之前,让模型学到比激励函数之後有更好的准确度。因此,今天就决定来做这个小实验,比较两者的差异。
实验一:Layer -> BN -> Act
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_before_act(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
return input_node, net
input_node, net = get_mobilenetV2_before_act((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
输出:
Epoch 51/100
loss: 0.0194 - sparse_categorical_accuracy: 0.9942 - val_loss: 0.8054 - val_sparse_categorical_accuracy: 0.8281
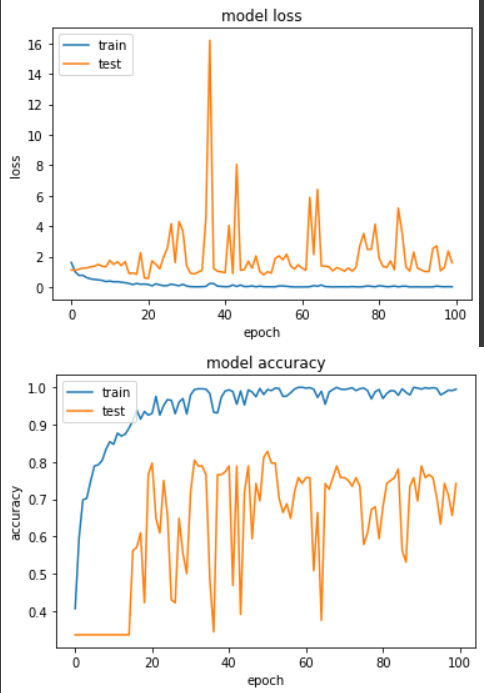
实验二:Layer -> Act -> BN
def bottleneck(net, filters, out_ch, strides, shortcut=True, zero_pad=False):
padding = 'valid' if zero_pad else 'same'
shortcut_net = net
net = tf.keras.layers.Conv2D(filters * 6, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
if zero_pad:
net = tf.keras.layers.ZeroPadding2D(padding=((0, 1), (0, 1)))(net)
net = tf.keras.layers.DepthwiseConv2D(3, strides=strides, use_bias=False, padding=padding)(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.Conv2D(out_ch, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
if shortcut:
net = tf.keras.layers.Add()([net, shortcut_net])
return net
def get_mobilenetV2_after_act(shape):
input_node = tf.keras.layers.Input(shape=shape)
net = tf.keras.layers.Conv2D(32, 3, (2, 2), use_bias=False, padding='same')(input_node)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.DepthwiseConv2D(3, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
net = tf.keras.layers.Conv2D(16, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.BatchNormalization()(net)
net = bottleneck(net, 16, 24, (2, 2), shortcut=False, zero_pad=True) # block_1
net = bottleneck(net, 24, 24, (1, 1), shortcut=True) # block_2
net = bottleneck(net, 24, 32, (2, 2), shortcut=False, zero_pad=True) # block_3
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_4
net = bottleneck(net, 32, 32, (1, 1), shortcut=True) # block_5
net = bottleneck(net, 32, 64, (2, 2), shortcut=False, zero_pad=True) # block_6
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_7
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_8
net = bottleneck(net, 64, 64, (1, 1), shortcut=True) # block_9
net = bottleneck(net, 64, 96, (1, 1), shortcut=False) # block_10
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_11
net = bottleneck(net, 96, 96, (1, 1), shortcut=True) # block_12
net = bottleneck(net, 96, 160, (2, 2), shortcut=False, zero_pad=True) # block_13
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_14
net = bottleneck(net, 160, 160, (1, 1), shortcut=True) # block_15
net = bottleneck(net, 160, 320, (1, 1), shortcut=False) # block_16
net = tf.keras.layers.Conv2D(1280, 1, use_bias=False, padding='same')(net)
net = tf.keras.layers.ReLU(max_value=6)(net)
net = tf.keras.layers.BatchNormalization()(net)
return input_node, net
input_node, net = get_mobilenetV2_after_act((224,224,3))
net = tf.keras.layers.GlobalAveragePooling2D()(net)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[input_node], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
输出:
Epoch 67/100
loss: 0.0035 - sparse_categorical_accuracy: 1.0000 - val_loss: 1.0461 - val_sparse_categorical_accuracy: 0.8203
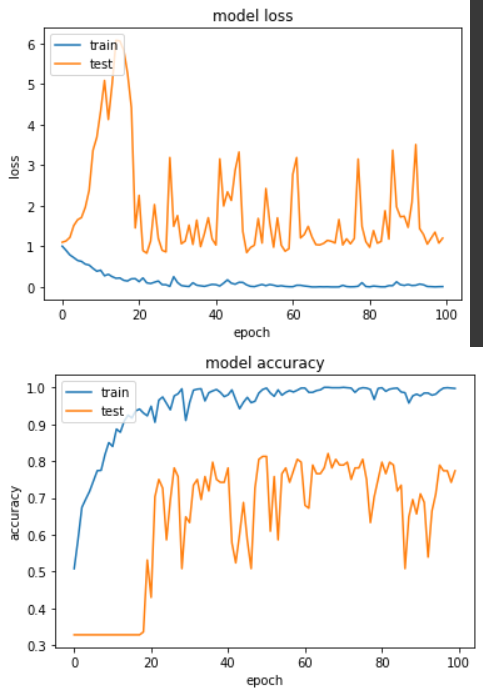
实验结果显示,两者的最佳准确度差不多,看来尽管把 BN 放在激励函数之後,还是可以让模型收敛。我自己实务上仍是倾像於把 BN 放在激励函数之前(实验一),让 BN 去学习 CNN/Dense 的权重。
Day 17 : PHP - MySQLi的面向过程和面向对象是什麽?又该如何做选择?
如标题,这篇想和大家聊聊MySQLi的「面向过程」和「面向对象」是什麽 我当初在学这里时,这个问题困...
Day 01 阿修补坑中
第一天先来聊聊我的背景以及为什麽我会想写这个主题 原本我是一名品保工程师,做了3、4年发现这份工作开...
Day3 什麽是Git?
大家好,我是乌木白,今天我们开始讲我们这次铁人赛的第一个技能,就是Git啦!先和大家声明我是把我自...
Day 28 - 使用 CDK 创建 CloudWatch Alarm 的含图告警同时发送到 LINE 与 Discord
昨天教大家怎麽简单的在 LINE Notify 上面看到 CloudWatch 的 Alarm,不过...
追求JS小姊姊系列 Day22 -- 工具人、姐妹不只身份的差别(中):从识别字开始讲起吧
前情提要 奇怪的事情,姐妹们疑似也有超能力。 方函式:表面上虽然看起来就是所谓的姐妹、工具人关系,但...