[Day 25] - 『转职工作的Lessons learned』 - Cube.js(I)
今天要介绍一下工作上有使用的到的另一项工具 - Cube.js。
Cube.js 是一个开源的API工具,主要是在做将资料分析後转换成图表。
官网的介绍如下:
Cube.js 旨在与无服务器数据仓库和查询引擎(如 Google BigQuery 和 AWS Athena)配合使用。多阶段查询方法使其适合处理数万亿个数据点。大多数现代 RDBMS 也可以与 Cube.js 一起使用,并且可以进一步调整性能。
使用 Cube.js,您可以在数据之上创建语义 API 层,管理访问控制、缓存和聚合数据。由於 Cube.js 与可视化无关,您可以使用任何前端库来构建您自己的自定义 UI。
下表显示旧有的的资料分析与Cube.js差异,Cube.js 支援无服务器资料仓库和大多数现代关系型资料库管理系统 (RDBMS)。
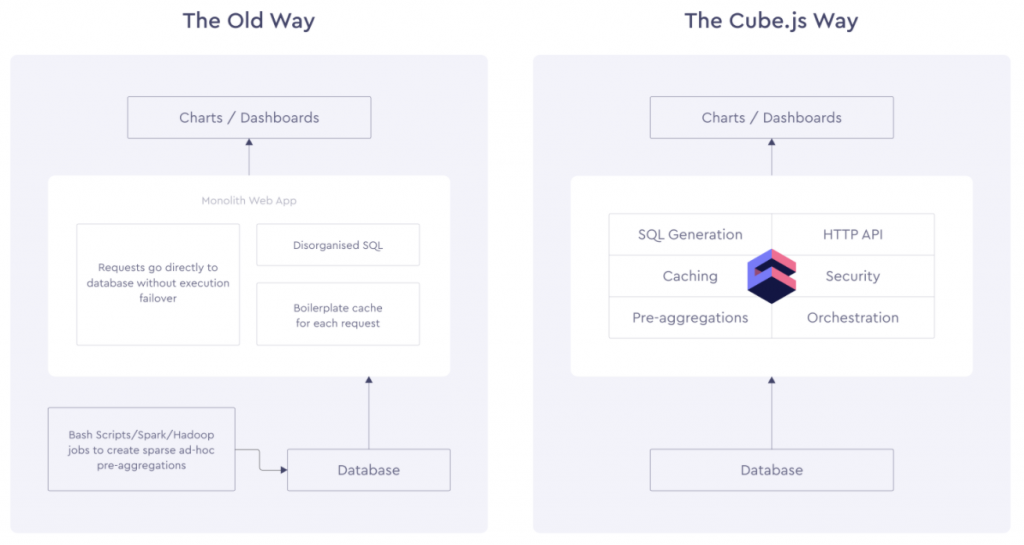
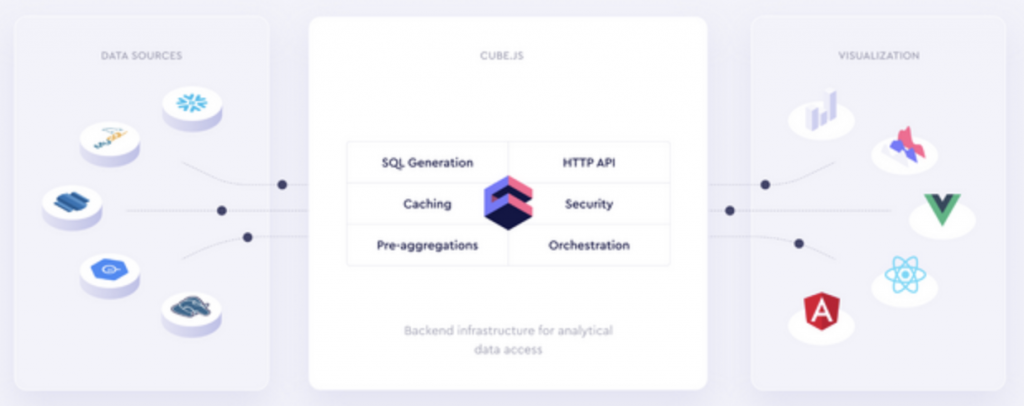
至於为什麽我们会去使用这个工具呢?原因是效能表现。如果储存的资料日益增大,那麽只有仅仅编写 SQL查询指标和维度进行,然後建模,最终也会发生问题的,因为效能可能表现上会差强人意。此时如果使用Cube.js这个工具来架构基础,那麽就能快速简便的解决这个问题(官网宣称)。
优点:
-
它的抽象层:配置 Cube.js 後,人们说他们不再需要担心效能优化、资源管理、SQL 专业知识等问题。许多人把 Cube.js 称为 “黑盒”,因为它的抽象层帮助他们专注於理解资料,而不是实施细节。
-
易於定制:由於 Cube.js 是视觉化的,它很容易与前端框架整合,建立看起来像使用者自己平台的解决方案。大多数商业平台(如 Looker、Tableau 等)需要更多的定制工作来与他们的基础设施整合。许多使用者说,定制的便利性与抽象层相结合,使他们能够减少资料分析平台的开发时间。
-
社群支援:在开始使用 Cube.js 时,人们通常会从社群成员那里得到帮助(特别是在我们的Slack),许多人提到社群支援是一个关键的入门资源。
以上摘录至https://www.gushiciku.cn/dl/1fpGT/zh-tw
Day 2 - API 文件导览、 Postman 测试取得 Nonce
在进行串接前,首先需要有定义串接的规格,例如:串接的协定 (HTTP、或走 FTP 档案交换等等)、...
IOS、Python自学心得30天 Day-20 .h5 to .tflite to .mlmodel
前言: 这一两天我一直很想把.h5档案或是.pb档案 直接转成Xcode可用的.mlmodel档案 ...
[Day19]程序菜鸟自学C++资料结构演算法 – 二元搜寻树(Binary Search Tree,BST)
前言:昨天先烧为带大家认识最简单的搜寻类型,今天要来介绍之前有稍微提到的二元搜寻树,并实作给大家看看...
Day 11 - 安装(ㄧ)Tiup工具
接下来让我们开始来实际安装TiDB。 TiDB在4.0版本之後推出了Tiup这个安装工具。功能十分齐...
【Day 3】分散式系统模型、容错、高可用
上一章我们了解了分散式系统是什麽、为什麽要让系统分散, 也大概知道分散式系统会遇到节点死掉、网路断掉...