Day25 - 静态模型 part3 (CNN)
今天的内容会说明将 attention 机制加入到昨天提到的 multi-scale CNN 当中。
CNN 中的 attention 机制是受到自然界中生物的视觉注意机制所启发。例如,人类能够以高分辨率专注於图像的特定区域,同时以低分辨率感知周围区域。此外,焦点区域可以以看似毫不费力的方式进行动态转移。为了能够使 CNN 架构
中不同特徵图的不同区域有不同的贡献值,我们在 CNN 模型中加入 attention 机制。
在模型架构中,attention module 的输入为 multi-scale CNN 第一层经过 max-out uni 取最大值後的feature map。attention module 由两层 max-pooling layer(pooling size: 2x2)及两层 upsampling layer(采样方式为双线性内插 Bilinear Interpolation)组成。其中所有的 max-pooling layer 及 upsampling layer 後面都会接着一层 conv layer,kernel size 皆为2x2,输出的 feature map 维度分别为30、20、20及10,最後在使用 softmax 进行转换。attention module 的输出会与 multi-scale CNN 的输出相乘,再将相乘的结果与原本 multi-scale CNN 的输出相加最後再传递至输出层,架构如图 1。
双线性内插 (Bilinear Interpolation) 为线性内插在二维直角网格的扩展,用於对双变
量函数(ex: x , y)进行内插。其核心概念是在两个方向上分别进行一次线性内插。
图 2 为双线性内插的示意图。
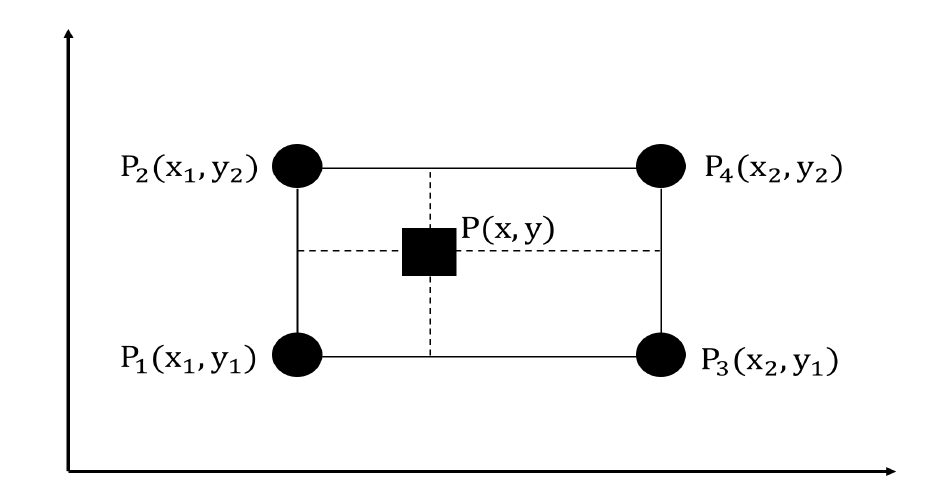
图 2: 双线性内插示意图。四个圆形的点(P1、P2、P3、P4)代表已知的资料点而正方形的点(P)代要进行内插的点
具体来说,假设我们要近似函数 f(.) 在点 P=(x,y) 的值。已知函数 f(.) 在点 、
、
、
的值,则函数 f(.) 在点 P=(x,y) 的双线性内插定义如下:
实际上在实作时可以直接透过 tensorflow 的 image resize 来完成
def interpolation(inputs, size):
return tf.image.resize_images(inputs, size, method=tf.image.ResizeMethod.BILINEAR)
method 参数的部份,详细说明可以参考这里。
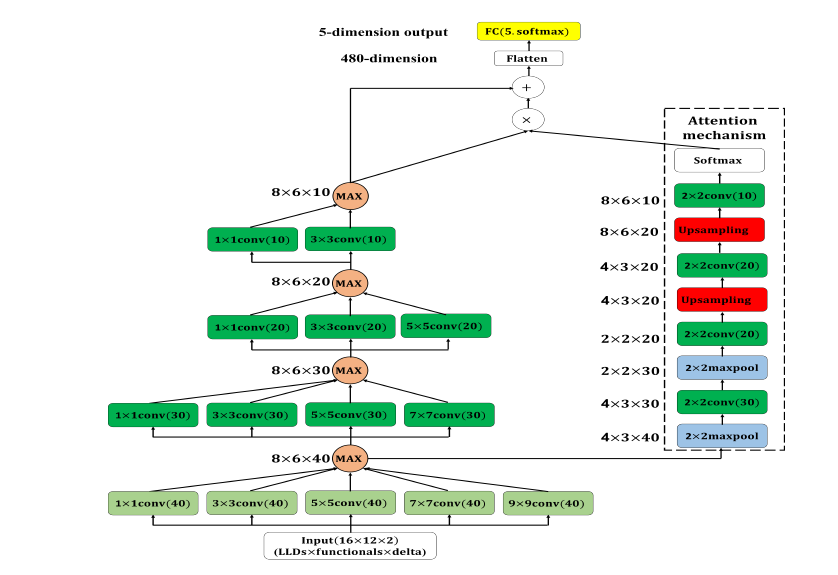
图 1: Multi-scale CNN with attention mechanism 静态模型。每一层卷积层後的activation function 使用 tanh 与 ReLU,所有卷积层 padding 方式皆为 zero-padding,浅绿色卷积层 stride=2;深绿色卷积层 stride=1
依照图 1 的架构转换成程序:
cnn_train_data = np.reshape(train_data, (train_data.shape[0], args.llds, args.functionals, args.delta))
cnn_test_data = np.reshape(test_data, (test_data.shape[0], args.llds, args.functionals, args.delta))
# 8x6x40
conv1_1 = Conv2D(filters=40,kernel_size=(1,1),strides=(2,2),padding='same', activation='relu', name='conv1_1')(cnn_input)
conv1_2 = Conv2D(filters=40,kernel_size=(3,3),strides=(2,2),padding='same', activation='relu', name='conv1_2')(cnn_input)
conv1_3 = Conv2D(filters=40,kernel_size=(5,5),strides=(2,2),padding='same', activation='relu', name='conv1_3')(cnn_input)
conv1_4 = Conv2D(filters=40,kernel_size=(7,7),strides=(2,2),padding='same', activation='relu', name='conv1_4')(cnn_input)
conv1_5 = Conv2D(filters=40,kernel_size=(9,9),strides=(2,2),padding='same', activation='relu', name='conv1_5')(cnn_input)
conv1_maxout = maximum([conv1_1, conv1_2, conv1_3, conv1_4, conv1_5], name='conv_max1')
#4x3x30
conv2_1 = Conv2D(filters=30,kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv2_1')(conv1_maxout)
conv2_2 = Conv2D(filters=30,kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv2_2')(conv1_maxout)
conv2_3 = Conv2D(filters=30,kernel_size=(5,5),strides=(1,1),padding='same', activation='relu', name='conv2_3')(conv1_maxout)
conv2_4 = Conv2D(filters=30,kernel_size=(7,7),strides=(1,1),padding='same', activation='relu', name='conv2_4')(conv1_maxout)
conv2_maxout = maximum([conv2_1, conv2_2, conv2_3, conv2_4], name='conv_max2')
#2x2x20
conv3_1 = Conv2D(filters=20,kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv3_1')(conv2_maxout)
conv3_2 = Conv2D(filters=20,kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv3_2')(conv2_maxout)
conv3_3 = Conv2D(filters=20,kernel_size=(5,5),strides=(1,1),padding='same', activation='relu', name='conv3_3')(conv2_maxout)
conv3_maxout = maximum([conv3_1, conv3_2, conv3_3], name='conv_max3')
#1x1x10
conv4_1 = Conv2D(filters=10, kernel_size=(1,1),strides=(1,1),padding='same', activation='relu', name='conv4_1')(conv3_maxout)
conv4_2 = Conv2D(filters=10, kernel_size=(3,3),strides=(1,1),padding='same', activation='relu', name='conv4_2')(conv3_maxout)
conv4_maxout = maximum([conv4_1, conv4_2], name='conv_max4')
# attention module (input: 8x6x40)
attention_pool_1 = MaxPooling2D(pool_size=(2,2), padding='same', name='att_pool1')(conv1_maxout)# 4x3x40
attention_conv_1 = Conv2D(filters=30, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv1')(attention_pool_1)# 4x3x30
attention_pool_2 = MaxPooling2D(pool_size=(2,2), padding='same', name='att_pool2')(attention_conv_1)#2x2x30
attention_conv_2 = Conv2D(filters=20, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv2')(attention_pool_2)#2x2x20
attention_interp_1 = Lambda(interpolation, arguments={'size': (4,3)}, name='att_up1')(attention_conv_2)# 4x3x20
attention_conv_3 = Conv2D(filters=20, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv3')(attention_interp_1)#4x3x20
attention_interp_2 = Lambda(interpolation, arguments={'size': (8,6)}, name='att_up2')(attention_conv_3)# 8x6x20
attention_conv_4 = Conv2D(filters=10, kernel_size=(2,2), padding='same', activation='relu', use_bias=False, name='att_conv4')(attention_interp_2)#8x6x1
attention_weights = Activation('softmax', name='attention_weights')(attention_conv_4)
attention_representation = multiply([conv4_maxout, attention_weights])
attention_add = add([conv4_maxout, attention_representation])
conv_flatten = Flatten()(conv4_maxout)# 480
output = Dense(units=args.classes, activation='softmax', name='output')(conv_flatten)
model = Model(inputs=cnn_input, outputs=output)
model.summary()
前半部的部分跟昨天的 multi-scale CNN 相同,增加的部分在於 attention module。
在说明完三种的 CNN 架构後,我们就来做个比较吧。在表 1 中可发现将 attention 机制应用於multi-scale CNN上并没有显着的影响,UA recall 仅从 46.1% 上升至 46.4%。主要原因应为应用於 CNN 的 attention 机制目的是要决定不同空间区域的贡献程度。然而,语音讯号的本质并非空间而是时间。
| Model | UA recall (tanh) | UA recall (ReLU) |
|---|---|---|
| Basic CNN | 44.1% | 43.6% |
| Multi-scale CNN | 46.1% | 45.3% |
| Multi-scale CNN with attention | 46.4% | 45.6% |
表 1: 三种 CNN 与不同 activation function 实验结果比较
我们再将最好的结果 (UA recall=46.4%) 列出其混淆矩阵如表 2
| / | A | E | N | P | R | UA recall |
|---|---|---|---|---|---|---|
| A | 382 | 85 | 96 | 33 | 15 | 62.5% |
| E | 336 | 746 | 345 | 63 | 18 | 49.5% |
| N | 748 | 977 | 2,788 | 770 | 94 | 51.9% |
| P | 13 | 9 | 52 | 135 | 6 | 62.8% |
| R | 113 | 81 | 190 | 133 | 29 | 5.3% |
| Avg.recall | - | - | - | - | - | 46.4% |
表 2: Multi-scale CNN with attention 分类结果混淆矩阵(A:angry, E:emphatic,
N:neutral, P:positive, R:rest
静态模型的部分就到这边了,明天开始将介绍动态模型的部分。
[Day 30] - 终成行男
呼,想当初在铁人赛开赛前还在犹豫到底要不要开赛呢? 参赛後是要写什麽主题呢? 一探 React Na...
show hand 下赌金似乎是好买法 - 肥羊波浪理论
肥羊波浪理论 标准型》以5%价格涨跌,卖买5%股票数量 频繁型》以2.5%价格涨跌,卖买2.5%股票...
[Day26] Micro Services
在前几天的 App Engine 与 K8S 中,或许我已经大致的提过 Micro Services...
Google Static Map Maker 静态地图 API 工具|专案实作
Google Static Map API 是将网页上需要的地图画面,以静态地图图片的方式显示。 优...
[Day01] 前言
身为一个商业设计的转职者,从懵懂到认识 HTML 与 CSS 之後,接着来到进入 JavaScrip...