[Day 19] 收集资料 — 你要对人家负责啊!
With data collection, ‘the sooner the better’ is always the best answer. – Marissa Mayer
前言
就像大家耳熟能详的 GIGO 所阐述的概念一样,我们收集来的训练资料以及标注它们的方式直接影响了 ML 系统的最终输出,而这与使用者体验息息相关。
为了避免糟糕的资料选择导致後续模型开发等步骤出师不利,甚至最终使得产品失败,我们必须从一开始就计画好如何收集高品质的资料,因此今天会说明以下要点:
- 了解使用者 (或应用) 并将需求转译成资料问题。
- 确保训练资料的涵盖范围与实际上线资料一致,且资料饱含可帮助预测的信息。
- 对高品质资料的取得、储存与监控负责任。
收集资料
收集资料时最重要的就是了解使用者,把他们的需求转译成资料问题 (Data Problem),才不会浪费时间收集用不到的资料,以 跑步路线推荐 app 为例:
首先要厘清使用者是谁?其需求为何?以及 ML 系统的目标为何?

而为了要把使用者需求转译为资料需求,可依序厘清:
- 资料是什麽?
以此例来说就可能是:- 来自 app 的跑步资料
- 当地地理资料
- 人口资料
- 需要什麽特徵?
以此例来说就可能是:- 跑者的人口资料
- 日期
- 跑步完成率
- 跑速
- 跑步距离与海拔变化
- 心率
- 需要的标签为何?
以此例来说就可能是:- 跑者是否接受 app 的建议
- 跑者对拒绝建议提供的意见
- 跑者对推荐的满意度
最终收集的资料结果可能如下:
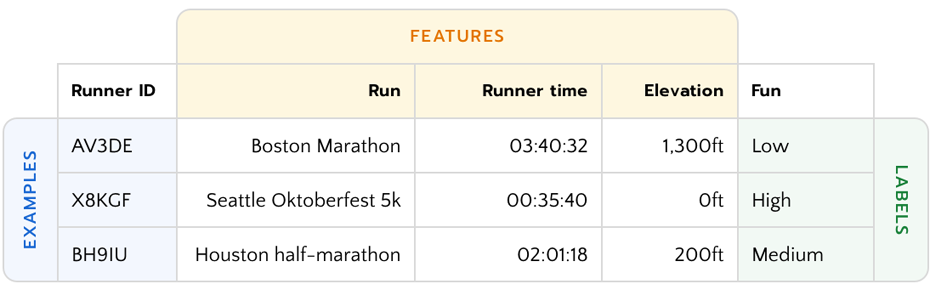
*图片来源:People + AI Guidebook — Data Collection + Evaluation
另外对收集来的资料要负责任,这包含了纪录来源、保障隐私以及避免歧视:
纪录来源
资料可能的来源有很多,要负责任地纪录清楚:

安全性
资料收集与管理不只与模型有关,更重要的是安全与隐私,前者是指确保个人资料 (Personally Identifiable Information) 安全的政策或方法,後者则是正确的使用、收集、保留、删除与储存这类资料。
其中确保资料安全的方法有:
- 让使用者自行选择哪些资料可以被收集。
- 确保资料不会在不经意间泄漏,例如显示在确认画面上。
- 遵守相关法规,例如 GDPR。
而透过以下方法则可以确保隐私:
- Aggregation:将独特的数值改成统计数值,例如把个人薪资改成平均薪资。
- Redactio:移除某部分资料使其难以拼凑出全貌。
公平性
必须在公平、可靠、透明、可解释间取得平衡,否则 ML 系统可能会让使用者失望,例如:
- Representational harm:增强或反映对某族群的刻板印象。
- Opportunity denial:系统的预测对现实生活产生负面影响。
- Disproportionate product failure:模型偏向对某族群输出某类结果。
- Harm by disadvantage:系统会给某类族群较不利的推论。
因此要时时注重公平性。
资料量,多少才够?
当 AI 团队与其他领域专家合作时,最常被问到的问题就是,要提供多少资料才行?
这时候通常都是依照 feature 数量来大致推估所需的资料量,但在电子报 Data-Centric AI Development, Part 3: Limit Data Collection Time 提出了另外一种想法 — 把「要花多久才能收集 m 个样本?」改为「在 d 天内可以收集多少资料?」,也就是改执行以下训练回圈:

这是因为首次训练、错误分析的时间通常都不长,别因为收集资料延宕整体进度,尽快进入训练模型的回圈中才是王道,等资料真的不够还有充足的时间再回头收集就好。
如果已经有过去的经验告诉我们需要多少资料就另当别论。
好啦,今天的内容就到这里,明天就来继续谈谈如何标注资料吧!

参考资料
- Coursera — Machine Learning Data Lifecycle in Production
- Coursera — Introduction to Machine Learning in Production
- Google, People + AI Guidebook — Data Collection + Evaluation
<<: Day 20:1566. Detect Pattern of Length M Repeated K or More Times
>>: D20/ 怎麽在 compose 与 non-compoe 间传资料 - Compose Side-Effect part 2
DAY 9:Worker Pool Pattern,就。很。Pool。
什麽是 Worker Pool Pattern? 设定好 pool 的 goroutine 数量,预...
Day 30 | 将flutter web 部署至 netlify
最後一天就来部署我们的flutter web吧,也算是这系列文中真的跟「web」唯一有关的一篇文XD...
自动化测试,让你上班拥有一杯咖啡的时间 | Day 29 - cypress 最佳实践
此系列文章会同步发文到个人部落格,有兴趣的读者可以前往观看喔。 选取元素 ⚠️ 避免使用会常常变的s...
Day3 - numpy(2) 基本索引
今天的重点 索引 基本索引: 先建立一个4x3的ndarray来让我们实际操作 阵列索引是由外而内的...
生存法则三:磨练远距工作者特殊技能
通常要一件事,自己一个人做是做是最快的,因为从构思、设计,只需要在自己大脑传递就完成了,执行的结果也...