Python 演算法 Day 14 - Evaluation & Performance Tuning
Chap.II Machine Learning 机器学习
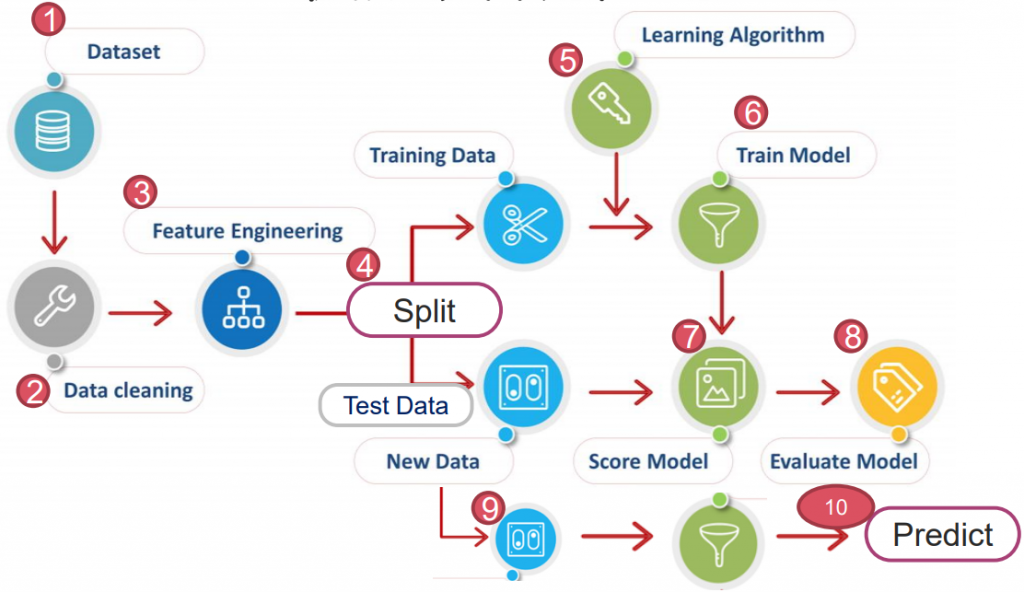
https://yourfreetemplates.com/free-machine-learning-diagram/
Part 4. Evaluation & Performance Tuning 评估与效能调校
4-1. Pipe Line 管线配置
将「缩放」「降维」「演算法」等规划进管线,方便一次性调校超参数,找出最佳效能。
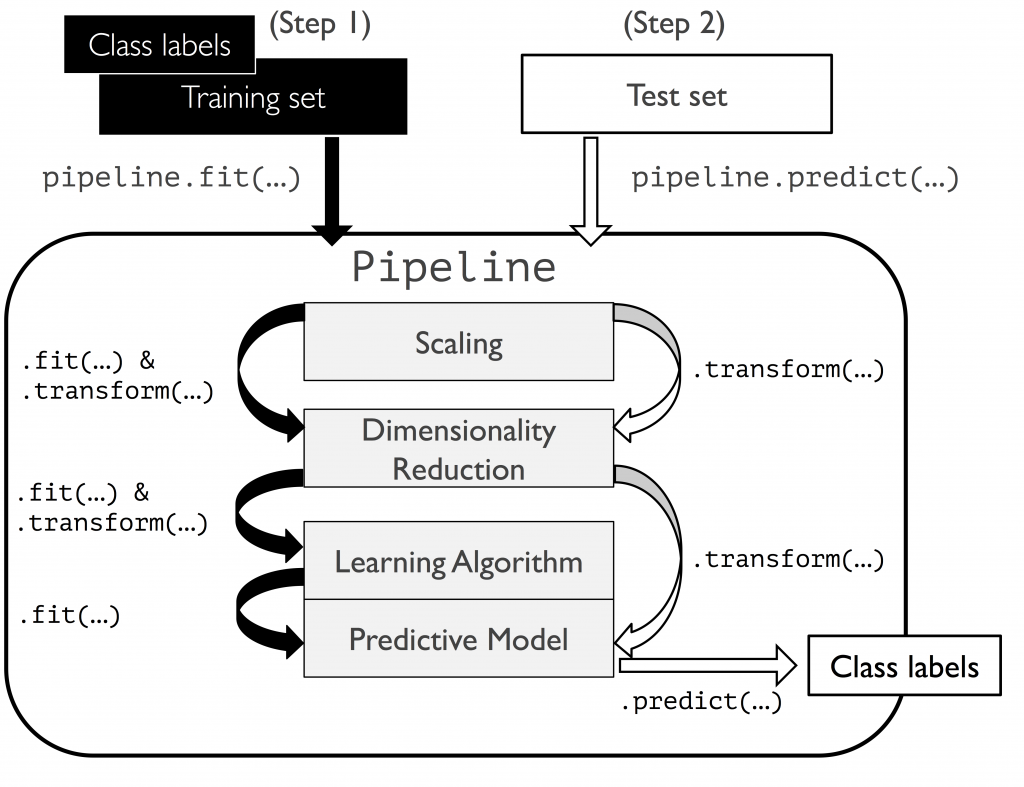
以乳癌为例:
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
管线化:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier as RFC
rfc_PL = make_pipeline(
StandardScaler(),
PCA(n_components=2),
RFC(n_estimators=100, criterion='gini', max_depth=3)
)
rfc_PL.fit(X_train, y_train)
rfc_PL.score(X_test, y_test)
>> 0.9239766081871345
我们使用 make_pipeline 中省去了转换资料放入标准化、PCA 与演算法等时间。
那麽,知道怎麽跑演算法,如何评估参数呢?
4-2. Inside Folds 内部折(参数调校)
GridSearchCV
对当前影响模型最大的参数调校直到最优,接着调校下个参数,至调整完毕。
优点:省时。
缺点:可能会调整模型为局部最优,而不是全局最优。
以鸢尾花为例:
from sklearn import svm, datasets
from sklearn.model_selection import GridSearchCV
ds = datasets.load_iris()
parameters = {'kernel':('linear', 'rbf', 'poly'), 'C':[0.1, 1, 10]}
svc = svm.SVC()
clf = GridSearchCV(svc, parameters, n_jobs=-1)
clf.fit(ds.data, ds.target)
# clf.best_params_
clf.best_estimator_
>> SVC(C=0.1, kernel='poly')
超参数
- estimator: 使用的演算法。
- param_grid: 为字典或者列表,即需要最优化的参数的取值。
- n_jobs: 平行执行的数量。当 n_jobs=-1 会使用最高核心数去跑。
- cv: 交叉验证参数,默认 None,使用三折交叉验证。
4-3. Outside Folds 外部折(模型评估)
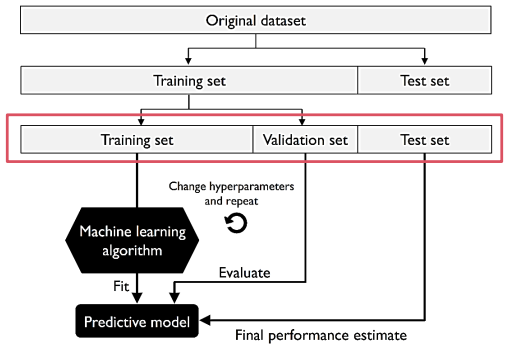
A. Holdout Cross Validation 保留交叉验证法
训练资料再次切成 Training & Validation,且在训练过程中不停用验证资料交叉验证。
优点:独立资料,验证与训练资料互不相干,仅需运算一次故成本低。
缺点:若切割不当,易造成效能评估不稳定。(可用 K 折交叉验证法解决)
以阿拉伯数字为例:
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train_n, x_test_n = X_train / 255.0, X_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
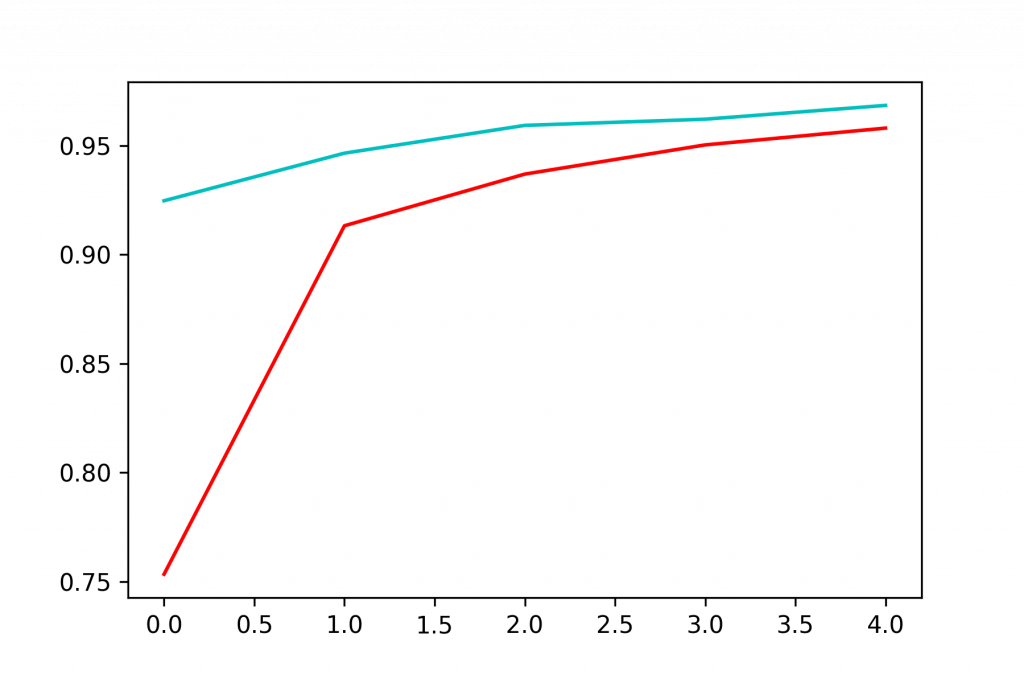
保留交叉验证法:
his = model.fit(X_train, y_train, epochs=5, validation_split=0.2)
import matplotlib.pyplot as plt
plt.plot(his.history['accuracy'], 'r', label='train')
plt.plot(his.history['val_accuracy'], 'c', label='validate')
plt.show()
B. K fold Cross Validation K 折交叉验证法
将资料切割成 K 份,以 K-1 做训练,1 做验证资料。
重复演算 K 次以得到 K 个模型与效能,最终把效能取平均值,作为模型的效能评估。
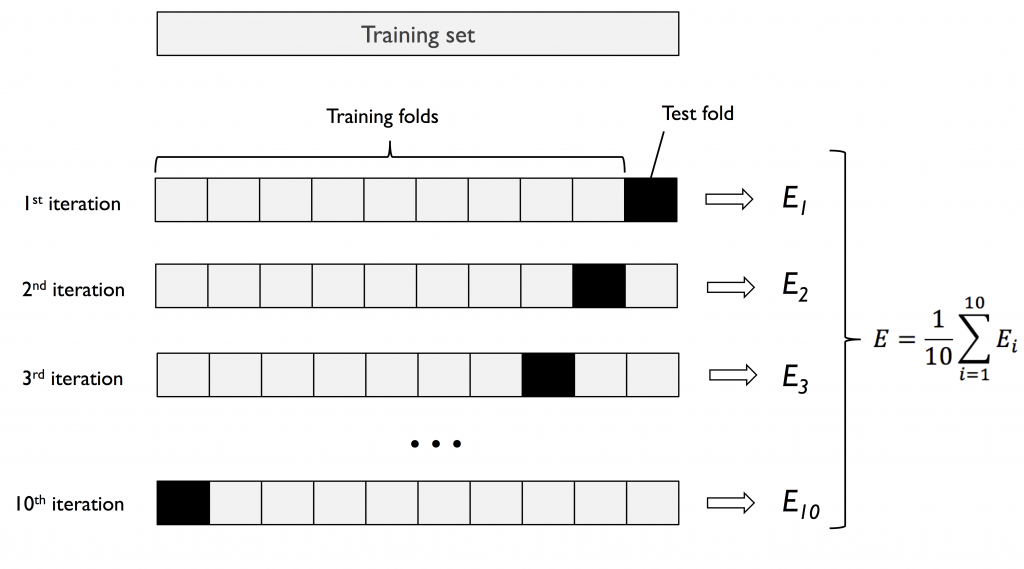
优点:K 值大,模型做效能评估时「偏差」小。可针对差异大类型资料做演算。
缺点:因重复数据多,运算时间长。且模型间非常类似可能造成「变异」大。
原始数据小:K 值大,以获得较准的效能评估。
原始数据大:K 值小(如 k=5),仍能获得不错的效能评估,最小化变异。
以乳癌为例:
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/'
'machine-learning-databases'
'/breast-cancer-wisconsin/wdbc.data', header=None)
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.transform(['M', 'B'])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20,
stratify=y,
random_state=1
)
制作管线:
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
lr_PL = make_pipeline(
StandardScaler(),
PCA(n_components=2),
LogisticRegression(random_state=1)
)
3. StratifiedKFold
比起一般 K 折,分层 K 折可以将原样本中数据依照比例拆分。
例如:台北市长投票人中,有 60% 是年长者 40% 是年轻人。
StratifiedKFold 会依 6:4 比例,尽量使每个分拆资料中皆含有年长者 & 年轻人。
import numpy as np
from sklearn.model_selection import StratifiedKFold
kf = StratifiedKFold(n_splits=10).split(X_train, y_train) # , random_state=1
score_list = []
for k, (train, test) in enumerate(kf):
# 把 train/test 形状印出
print(train.shape, test.shape)
# 切割资料丢入演算法
lr_PL.fit(X_train[train], y_train[train])
# 计算每一折的分数
score = lr_PL.score(X_train[test], y_train[test])
score_list.append(score)
print(f'Fold: {k+1:2d}, Class dist.: {np.bincount(y_train[train])}, Acc: {score:.3f}')
print(f'\nCV accuracy: {np.mean(score_list):.3f} +/- {np.std(score_list):.3f}')

超参数:
n_splits: 拆成几份
C. cross_val_score 简化 K 折
顾名思义,就是简单版的 K 折
# cross_val_score 简化 K 折
from sklearn.model_selection import cross_val_score
# 这边也可以把超参数 'cv' 的位置,用原本的 K 折取代。
scores = cross_val_score(lr_PL, X, y, cv=10)
scores
>> array([0.96491228, 0.89473684, 0.96491228, 0.94736842, 0.94736842,
0.94736842, 0.92982456, 0.98245614, 0.98245614, 0.98214286])
print(f'CV accuracy: {np.mean(scores):.3f} +/- {np.std(scores):.3f}')
>> CV accuracy: 0.954 +/- 0.026
结论:
- PipeLine:使演算法如流水线般生产,省略多行程序码。
- GridSearchCV:可将演算法超参数轮流丢入演算法中求最佳化。
- Cross Validation:将原始资料切割并用於验算,并以平均评分作为模型评分,减少评估模型偏差。
.
.
.
.
.
Homework:
使用内建 wine,试着用 pipeline、Cross Validation,写个回圈以操作演示过的演算法。
<<: 【Vue】2个步骤检测路由 | Path Ranker
[Lesson10] Machine Learning
今天要来试着使用Firebase的机器学习套件,点击左边的Machine Learning 可以看到...
如何自己设计一套ERP程序 前传-写ERP之前要决定的20件事 决定ERP後台资料库
第3个决定 决定ERP後台资料库 在所有资料库里笔者用过Oracle 和MS SQL,这2者使用时间...
Day25- 如何盘中计算技术指标且发送讯号到line: 成果示范
今天要整合先前所学,使用colab盘中即时计算技术指标,当技术指标达到我们要的条件时,发送讯息到li...
Unity自主学习(十八):认识Unity介面(9)
昨天看完了"Transform"栏位之後,接下来"属性检视区"...
[自然语言处理基础] 语法分析与资讯检索 (II)
前言 上一回我们将词性标签依序排列建构出片语组块( phrase chunk ),描绘出相应的分析树...