Day26-Kaggle Titanic迈进前5% part(3)
前面两天,我们对需要用的栏位做了特徵工程、缺失值的补充、值得转换等
我们已经将资料前处理做得差不多了,接着在做一些动作就可以拿下去train了
将DataFram转成ndarray:
选择要使用的栏位透过values属性获得ndarray的资料型态
透过布林索引及栏位的选择分成train_x、train_y、test_x
虽然我们前面有处理过Fare这个栏位,但我发现加入Fare这个栏位满影响训练结果的,我猜~可能是因为我没对此栏位观察得很好吧! 反正我就是不要用此栏位

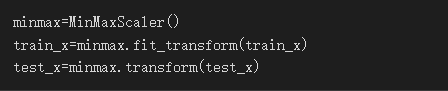
正规化
正规化以利训练,我使用了MinMaxScaler这个方法
转为tensor
一定要记得转成tensor,不然是不能train的

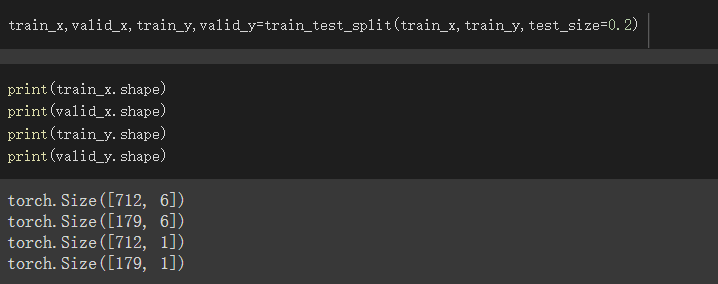
分成train_set、validate_set
比例我设成train_set占8成,validate_set占2成
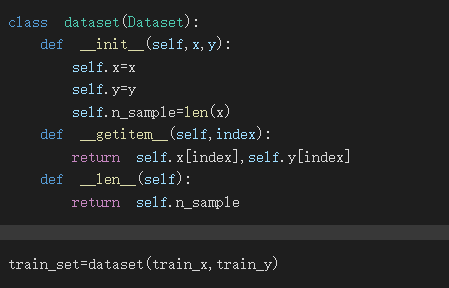
Dataset
DataLoader
batch_size我设成100,shuffle记得设成True,因为这要拿下去train

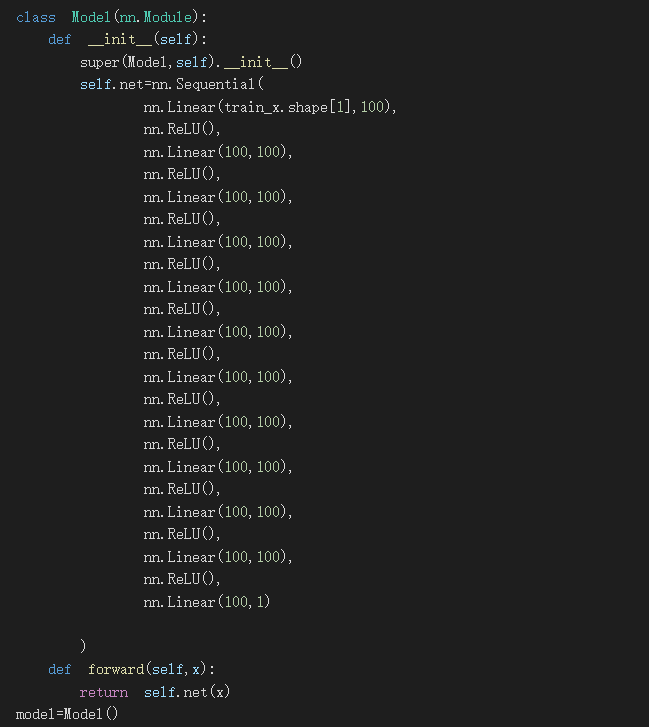
model
critirion、optimizer、epoch、n_batch
设置n_batch=len(train_loader)是为了好看资料的训练过程
其他的以前都有说过就不解释了

设定best_acc变数
我设定了一个变数为best_acc,并指派为0
此变数是为了之後训练来记录最好的model并做储存
等一下看训练过程就能知道实际我是怎麽操作的

开始训练model
这部分我会分成三个部分来讲解
我分别用了白色框、黄色框、红色框分组
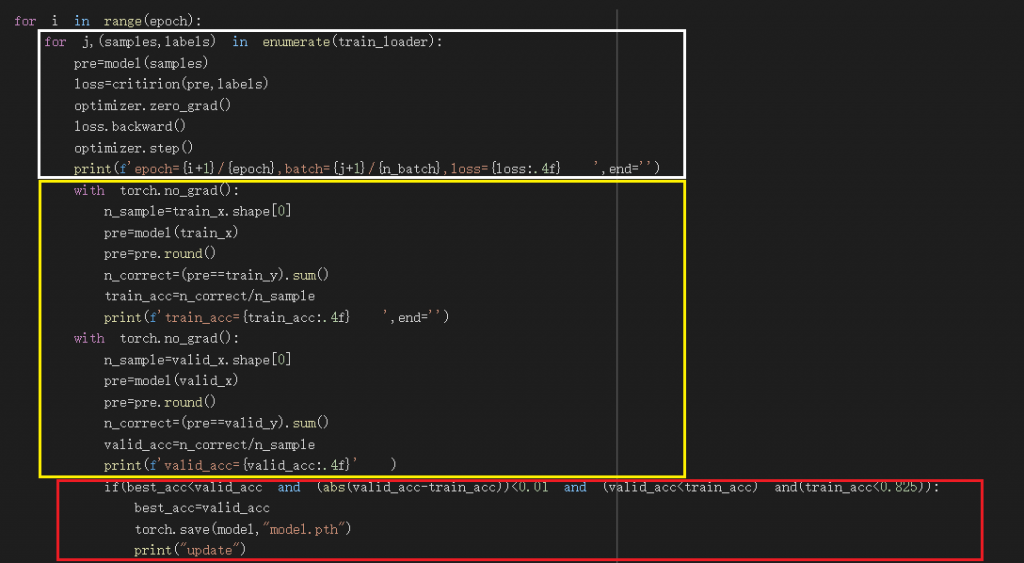
白色框:
白色框为训练的过程及程序码,会print第几个epoch、第几个batch、loss的数值

黄色框:
黄色框有两个with torch.no_grad():
上面的部分为将training用的资料放入现在的模型并print出正确率
下面的部分为将validate用的资料放入现在的模型并print出正确率
pre.round()会将数值做四舍五入,因为我们要预测的数值不是1就是0来判断有无生存
n_correct=(pre==train_y).sum()会算出答案正确的个数

红色框:
这里设定了我储存model的条件,这里就有用到我前面设定的best_acc这个变数
best_acc用来储存最好的valid_acc
valid_acc黄色框里所算出的验证集正确率
train_acc黄色框里所算出的训练集正确率

解释我if判断式里都放了什麽
best_acc < valid_acc 成立时,表示新的验证集正确率比best_acc还高
abs(valid_acc-train_acc) < 0.01 成立时,表示验证集正确率与训练集正确率差距小於0.01,这是一个避免过度拟合的设定
valid_acc < train_acc 成立时,表示验证集正确率小於训练集正确率,因为这场来说,在训练时训练集正确率不会比验证集正确率还高,如果训练集正确率大於验证集正确率,只是model刚好符合验证集的资料状况
train_acc < 0.825 ,此项是避免让model过度拟合的设定,因为在我观察训练的过程,大部分验证集的正确率到後来都位於0.8~0.825之间,几乎无法再有提升,很少有大於0.83的正确率,表示如过大於0.83大概都只是model刚好符合验证集的资料状况
train_acc < 0.825 ,abs(valid_acc-train_acc) < 0.01,此两个判别的配合使我们能储存到一个不会过度拟合、正确率又高的model
载入model并输出答案
载入模型

算出答案并制作成DataFrame

输出CSV档
pre=pre.view(-1).numpy().astype(np.int)这段程序码我解释一下
原本model输出的pre为二维,透过view方法转成1维
numpy将tensor型态转乘ndarray,astype改变资料型态

之後就可以交上kaggle罗~
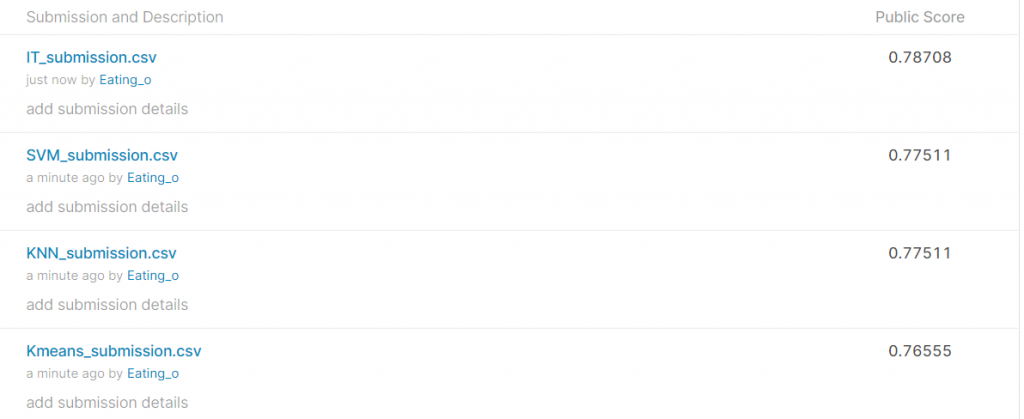
缴交结果
IT_submission 为DNN的训练结果(就是本文章的结果)
SVM_submission 为SVM的训练结果(後面文章会写)
KNN_submission 为KNN的训练结果 (後面文章会写)
Kmeans_submission 为Kmeans的训练结果(後面文章会写)
此全部都用相同的资料前处理
送上整个资料处理及训练过程
https://colab.research.google.com/drive/1l--rkdk0sCxrEAGyETSxFCMrJmS147tX?usp=sharing
>>: 自动化 End-End 测试 Nightwatch.js 之踩雷笔记:上传档案II
[神经机器翻译理论与实作] Google Translate的神奇武器- Seq2Seq (III)
前言 今天继续我们未完成的建模大业吧! 我们要建立的seq2seq模型由LSTM编码器与解码器串接而...
Day30 laravel Log 纪录request,response
Day30 laravel Log 纪录request,response 历经千辛万苦终於来到铁人赛...
Day 10【连动 MetaMask - Login Flow & Extension Check】The strongest password ever.
【前言】 终於要进到後端的部分啦!一样先来看 Project 分析,这几天的内容会环绕在第一步**...
关於URL encode
缘由: 开发时常常会遇到要对api传送参数的状况, 但常常都是传送String Int Bool等,...
Day 16 实作测试 (2)
前言 昨天我们写好了测试的 model,今天就来用他实作吧。 test_main 我们先从最简单的 ...