【13】模型套不套用资料增强 (Data Augmentation) 的比较实验
资料增强(Data Augmentation),是一个当今天资料集样本不多时,透过调整亮度、剪裁、角度等手法来增加多样性的好方法,Tensorflow 的 tf.image.random_* API 提供了不少资料增强的方法,让我们在训练模型时可以使用。
这次我简单介绍几个 API 并看看,这几种 Augmentation 方式会产生什麽样的效果。
def aug_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, (224,224))
flip_image = tf.image.random_flip_left_right(image)
flip_image = tf.image.random_flip_up_down(flip_image)
brt_img = tf.image.random_brightness(flip_image, 70)
brt_img = tf.clip_by_value(brt_img, clip_value_min=0.0, clip_value_max=255.0)
sat_img = tf.image.random_saturation(brt_img, 0.7, 1.5)
sat_img = tf.clip_by_value(sat_img, clip_value_min=0.0, clip_value_max=255.0)
cts_img = tf.image.random_contrast(sat_img, 0.6, 1.4)
cts_img = tf.clip_by_value(cts_img, clip_value_min=0.0, clip_value_max=255.0)
return image, flip_image, brt_img, sat_img, cts_img
random_flip:
就是随机上下左右颠倒,像这次的资料集是花的辨识,花本身就没有一定的方向性,就很适合拿来使用,但如果今天的资料集是猫狗二分类,那麽只需要左右颠倒即可。
random_brightness:
提供一个 max_delta 的值,会将图片每个像数乘上这个的变化量,要注意的是,如果今天你的图片已经先 normalize 到 [0.0, 1.0] 之间了,那这个值可以指设0.1就会产生很大的亮度差异,但如果今天图片的范围是[0, 255],那就需要设定比如70这样大的数值去产生亮度差异。
random_saturation:
提供上限 upper 和下限 lower 来决定图片的饱和度。
random_contrast:
和 random_saturation 雷同,对图片随机的对比度。
我们印出实际的图片变化
原图:
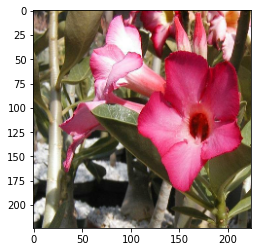
随机颠倒:
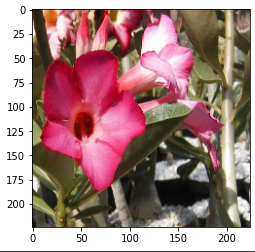
随机亮度:
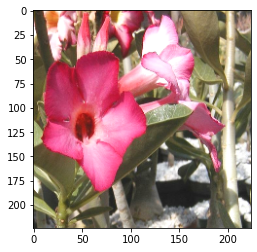
随机饱和度:
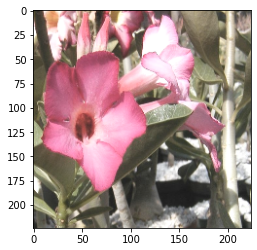
随机对比度:
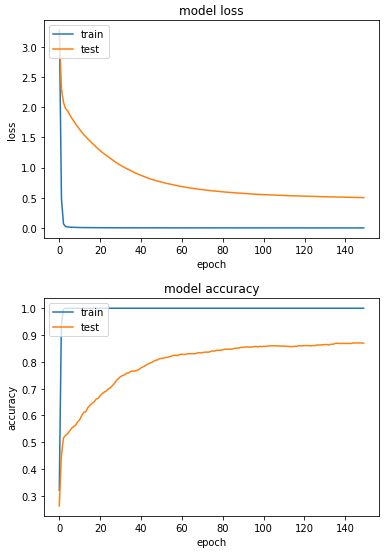
检查完图片都该有的变化後,我们先跑一次不做任何资料增强的训练:
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
最佳成绩:
loss: 5.2436e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.5029 - val_sparse_categorical_accuracy: 0.8706
接下来,跑一下套用资料增强後的模型:
def aug_img(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.random_flip_left_right(image)
image = tf.image.random_flip_up_down(image)
image = tf.image.resize(image, (224,224))
image = tf.image.random_brightness(image, 70)
image = tf.image.random_saturation(image, 0.7, 1.5)
image = tf.image.random_contrast(image, 0.6, 1.4)
image = tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=255.0)
return image / 255., label
ds_train = train_split.map(
aug_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_train = ds_train.cache()
ds_train = ds_train.shuffle(SHUFFLE_SIZE)
ds_train = ds_train.batch(BATCH_SIZE)
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = test_split.map(
normalize_img, num_parallel_calls=tf.data.experimental.AUTOTUNE)
ds_test = ds_test.batch(BATCH_SIZE)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
base = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights='imagenet')
net = tf.keras.layers.GlobalAveragePooling2D()(base.output)
net = tf.keras.layers.Dense(NUM_OF_CLASS)(net)
model = tf.keras.Model(inputs=[base.input], outputs=[net])
model.compile(
optimizer=tf.keras.optimizers.SGD(LR),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
start = timeit.default_timer()
history = model.fit(
ds_train,
epochs=EPOCHS,
validation_data=ds_test,
verbose=True)
产出:
loss: 5.2807e-04 - sparse_categorical_accuracy: 1.0000 - val_loss: 0.6019 - val_sparse_categorical_accuracy: 0.8422
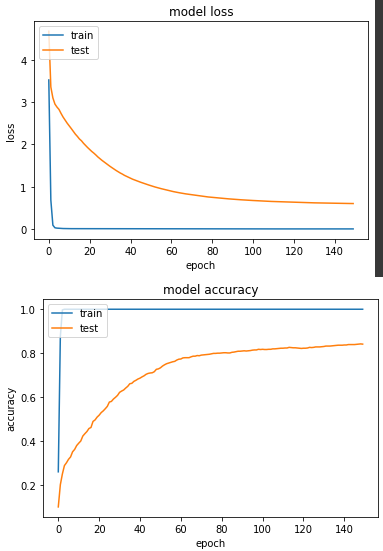
这次实验结果显示,最终的成绩并没有第一个模型好,相比准确度低了3%,但也不致於差到哪里去,资料增强仍然是一个我实务上常使用的方法。
<<: .NET Core第26天_ScriptTagHelper的使用
>>: 【Day 13】 实作 - 透过 AWS 服务 - QuickSight 建立互动式仪表板 ( 1 )
Day 14 event
第~14~天~罗~ 假如有开发过 Web 的都知道, 假如要设定按钮按下後的动作, 可在 html ...
赋权-团队里,没有人是局外人
当了team leader或者主管後,你有没有发现很多人大大小小的事情都跑来问你? 一度怀疑为什麽同...
[Android Studio 30天自我挑战] 利用Button切换ImageView的图片
上一篇讲到ImageView,这篇利用Button切换ImageView的图片, 可以让图片跳至上一...
Day 21 : 笔记篇 08 — 数位笔记太多很凌乱怎麽办?使用 MOC 架构有系统地管理数百则的数位笔记
一、当笔记愈来愈多时,会发生什麽问题? 多数人使用笔记软件或是文件愈来愈多时一定都会遭遇相同问题:想...
大人也舍不得离开的公园 — 共融游乐场 Inclusive Playground
生活中有大大小小的设计,也许就在你我的日常中却未曾发现,其中一项替城市街景增添设计风采的设施就是公园...