[自然语言处理基础] 语法分析与资讯检索 (I)
前言
前一回我们利用 WordNetLemmatizer 来还原词条的衍生形体,在这之中我们引入了一项神奇武器而顺利地还原词形,今天我们就来揭开它神秘面纱!

词性标注(POS Tagging)
词性(Part-of-Speech, POS)与语法分析(Syntactic Analysis)
在语言学中,单词被依照其功能以及词形变化(inflection)分类为不同的词性(Part of Speech, POS)。常见的词性包含了名词、动词、形容词、副词、介系词等等,如「 In God we trust. 」这句英文就由介系词( in ) + 名词( God ) + 代名词( we )+ 动词( trust ) 所依序构成,其句法(syntax)有别於由代名词、动词、介系词、名词依序构成的「 We trust in God. 」。我们将以词性作为出发点,依循文法规则,进而分析文句的架构,这个过程称为语法分析(syntactic analysis)。
在电脑科学和语言学中,语法分析(英语:syntactic analysis,也叫 parsing)是根据某种给定的形式文法对由单词序列(如英语单词序列)构成的输入文字进行分析并确定其语法结构的一种过程。
原文出处:语法分析| Wikipedia
英文里常见的词性
使用 NLTK 标注词性
当我们将句子分割成小单位,便可以利用 NLTK 工具箱中内建的函式 pos_tag() 依据词性来标记每一个词条:
from nltk import pos_tag
nltk.download("averaged_perceptron_tagger")
tokenised_sent = ["their", "decision", "makes", "no", "economic", "sense"]
# POS tagging
pos_tagged_sent = pos_tag(tokenised_sent)
print("POS tagged sentence:\n{}".format(pos_tagged_sent))
执行结果:

我们可以发现每个单词的词性都被标示出来:(关於以下词性代号,可参照 Part-of-Speech Tags)
- their → <PRP$> (所有格代名词)
- decision → <NN> (名词)
- makes → <VBZ> (动词,第三人称现在式)
- no → <DT> (限定词)
- economic → <JJ> (形容词)
- sense → <NN> (名词)
语块分析(Chunk Parsing)
相信在英文课堂上老师带领着学生分解文句结构,框选出名词子句、形容词子句、分词构句等等,是大多数台湾高中生的共同记忆。今天,我们要带领读者重温旧梦,将冗长的文句依照子结构进行文法拆解。
句构与分析树(Parse Tree)
语言具有层次结构,由大高到低可依序分为:句子 → 子句 → 片语 → 单词。
我们可以将句子的文法结构,依照层次高低描绘成分析树(又称具体语法树,与抽象语法树不同)。下图是用来描绘句子「 Their decision makes no economic sense. 」的分析树:

我们偶尔也会见到两句构一致的句子:
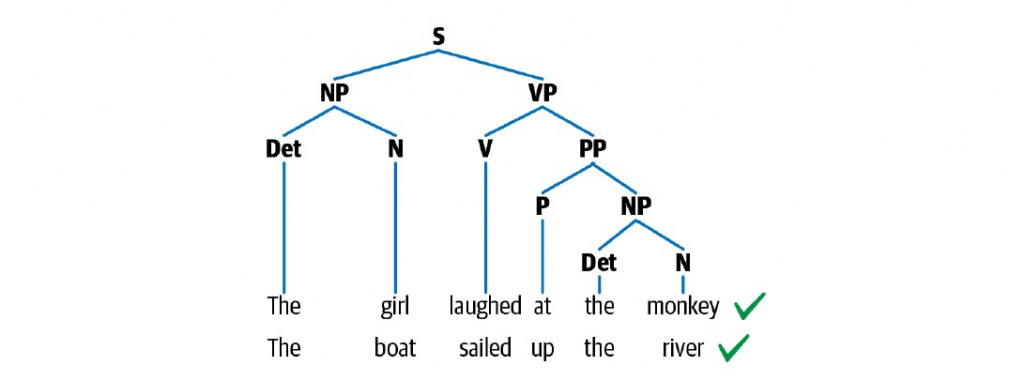
图片来源:
Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems
语义组块(Phrase Chunking)
句构的层次描述可以很简单,也可以很复杂,取决於我们如何「分块( chunking )」。我们可以依照片语或子句的文法结构指定语义组块,透过语法剖析器( parser )逐步检查语法(使用正则表达式比对字串),从而产生描述层次结构的分析树。我们将示范以名词片语以及动词片语两个简单的文法结构来实践分块:
首先我们引入剖析器类别:
from nltk import RegexpParser
我们可利用词性标签( POS tags )描述位居单词上一层的片语结构,并建立组块:
-
名词片语:
指的是具有名词作用的单词或词组,如下:- kids : <NNS>
- a programmer : <DT> + <NN>
- the wonderful day: <DT> + <JJ> + <NN>
-
a smart, energetic woman : <DT> + <JJ> + <JJ> + <NN>
我们可以观察出,名词片语的文法在正则表达式写为:<DT>?<JJ>*<NN.?>
以下我们描述名词片语分块并解析句子:
# given a word tokenised sentence tokenised_sent = ["their", "decision", "makes", "no", "economic", "sense"] # POS tagging pos_tagged_sent = pos_tag(tokenised_sent) # specifying the formal grammar of an noun phrase: "grammar_name: {RegEx}" np_chunk_grammar = "NP: {<DT>?<JJ>*<NN.?>}" # building its parser np_chunk_parser = RegexpParser(np_chunk_grammar) # chunk parsing a sentence np_chunked_sent = np_chunk_parser.parse(pos_tagged_sent) # visualising parsing result np_chunked_sent.draw()执行结果:

-
动词片语:
指的是由单独一个动词或一个动词与助动词(可多个)所构成的结构,如下:- spoke the sneaky creepy politician: <VBD> + <DT> + <JJ> + <JJ> + <NN>
- the sneaky creepy politician spoke: <DT> + <JJ> + <JJ> + <NN> + <VBD>
- the sneaky creepy politician spoke arrogantly: <DT> + <JJ> + <JJ> + <NN> + <VBD> + <RB>
动词片语的结构较为多样,我们姑且整理出其两个正则表达式:
- 1st kind of VB : <VB.?><DT>?<JJ*><NN><RB.?>?
-
2nd kind of VB :<DT>?<JJ*><NN><VB.?><RB.?>?
我们先利用第一种动词片语进行解析:
# specifying 1st formal grammar of a verb phrase vp_chunk_grammar_1 = "VP_1: {<DT>?<JJ>*<NN.?><VB.?><RB.?>?}" # building its parsers vp_chunk_parser_1 = RegexpParser(vp_chunk_grammar_1) # visualising parsing result vp_chunk_parser_1.draw()执行结果:
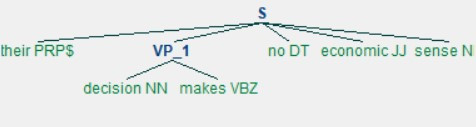
接下来试试第二种顺序:# specifying 2nd formal grammar of a verb phrase vp_chunk_grammar_2 = "VP_2: {<VB.?><DT>?<JJ>*<NN.?><RB.?>?}" vp_chunk_parser_2 = RegexpParser(vp_chunk_grammar_2) # visualising parsing result vp_chunk_parser_2.draw()执行结果:

语义组块刻划了句子的文法结构,我们亦可直白地说:不一样的组块会长出外型不同的树。这也让我们得以因应不同的需求,建立不同的片语或子句分块,客制化不一样的分析树,进而从多元的角度剖析字里行间蕴藏的讯息。今天的介绍就先告一段落,明天将会介绍进阶的分块描述以及如何藉由简短的字块就能对文本进行资讯检索。明天再见,各位!
阅读更多
>>: [DAY 1] _ ARM-M0架构MCU之韧体开发教学规划
# JS杂食-06--小实作-1: Star Calculator
参考资料1:MDN — the Mozilla Developer Network 参考资料2:0...
[Day29] 沟通之术 - 老板篇
今天是倒数第二天了~这个系列也快结束了,今天就以跟老板相处的过程时,老板给的提点来做个小结尾吧! 前...
Basic Customization
Basic Customation 昨天概略地提到了几种客制化的选项, 今天主要介绍两种 Custo...
Day18 - (补上昨天程序码) + BBT介绍
大家好,我是长风青云。早起跟朋友约、下午无缝接轨去帮弟弟搬宿、晚上一回到家就开始做ppt和发片。累瘫...
[DAY 08] Elastic Load Balancer
ELB (Elastic Load Balancer) ELB 是一个托管的 load balanc...