Day 6 - TiKV架构
TiKV Server是负责保存数据资料,采key-value模式储存,且key的排列是二进制有序的。这部分TiDB是采用RockDB来控制,RockDB是Facebook以Google的levelDB为基础再开发的一套key-value储存引擎。这部分交给专业的来,所以TiDB就没有另外再自行开发一套。
另外TiKV透过了实作Raft协议让资料产生副本,分散在每一个Tikv node上,副本通常是3份。资料会先写入raft log中,然後透过协议同步复制到其他node上,然後再写入rockDB,最终透过RockDB的机制flush到disk中。这样一个node挂了还有其他node可以使用。
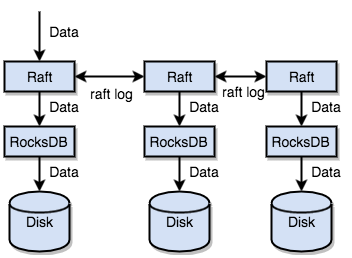
引用pingcap官网架构图
前面提到key的排列是有序的,而TiKV会依据设定的大小将key-value切成一小段,每一段称为Region,每一段的范围是[Key1,Keyn),即包括Key1到Keyn之间不包括keyn。
如图所示 资料会被切成大小相近的四份(R1~R4)。而这四个Region会被平均分布到三个node上,如下图node1有R1与R2,而node2中有R3,node3则有R4。这部分是PD Server做的调度,我们放到後面介绍PD的时候再解释。
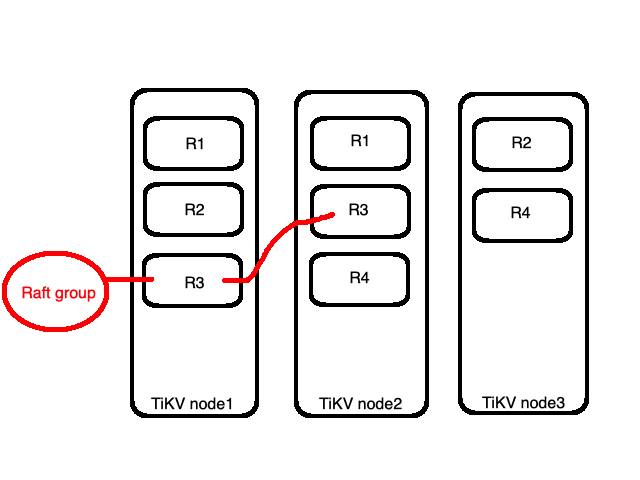
以上图为例,node1与node2都有R3,则是我们前面提到的副本也被称作replica,是以Region为单位做副本机制。而全部的R3统称为一个Raft group。一个Raft group里头会有一个leader与多个follower,预设所有读跟写的操作都会透过leader,写的部分会先写入leader然後复制到follower,读的部分就只要在leader读。
有没有发现这样的机制可能会造成的问题?瓶颈有可能会卡在leader身上,所以目前的版本有支援新的功能Follower Read,藉以分散leader的loading。
除此之外TiKV还可以透过Coprocessor为TiDB分担部分的计算,也就是前面讨论TiDB架构的时候提到的物理优化计划的执行者。
<<: Day-13 发动了革命的童养媳少女!打开 PlayStation 於新电视上重启革命之光
Day 10 不要小看附件
在隧道中,只朝着洞口的那道微光前进,忘了身旁的一切,总是认为爬离黑暗,才能重现光明,但是,就因为这样...
Visual Studio连线MySQL问题_解决办法
问题描述: 使用Visual Studio连线MySQL出现报错 错误讯息如下 「System.IO...
【Day11】- 递回Recursion
递回(Recursion)的概念是将一个大的问题,分割成许多小问题去解决。而从程序设计角度来看,函式...
推论 & 聚合( Inference and Aggregation)
-聚合功能 分区(Partitioning) 对数据或数据库进行分区是指将数据集分成多个部分并分别...
Encapsulation
本篇同步发文於个人网站: Encapsulation This article references...