爬虫怎麽爬 从零开始的爬虫自学 DAY23 python网路爬虫开爬-5程序优化
前言
各位早安,书接上回我们学会换页爬取文章标题了,今天我们要对程序码进行一些改良,使其更符合我们的需求,也更方便使用
开爬-优化
今天我们要做的就是优化昨天的程序增加一些功能
昨天的程序码
import requests
import bs4
def getData(url):
headers = {"cookie" : "over18=1"}
#建立headers用来放要附加的cookie
request = requests.get(url,headers = headers)
#将网页资料利用requests套件GET下来并附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
for title in titles:
if title.a != None:
print(title.a.text)
#利用for回圈印出全部并筛选掉已被删除的文章
prePage = data.find("a", class_ = "btn wide", text = "‹ 上页")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上页按钮内URL
return newUrl
#回传newUrl出去
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT领养版的网页原始码
for i in range(1,4,1):
url = getData(url)
#利用for回圈执行getData()函式3次
先从简单的开始
首先就是昨天撷取下来的资料不好阅读 密密麻麻的很长
所以我们再执行函式的 for 回圈加个分隔线更方便看
for i in range(1,4,1):
url = getData(url)
print("---------------第"+str(i)+"页---------------")
#利用for回圈执行getData()函式3次
执行效果
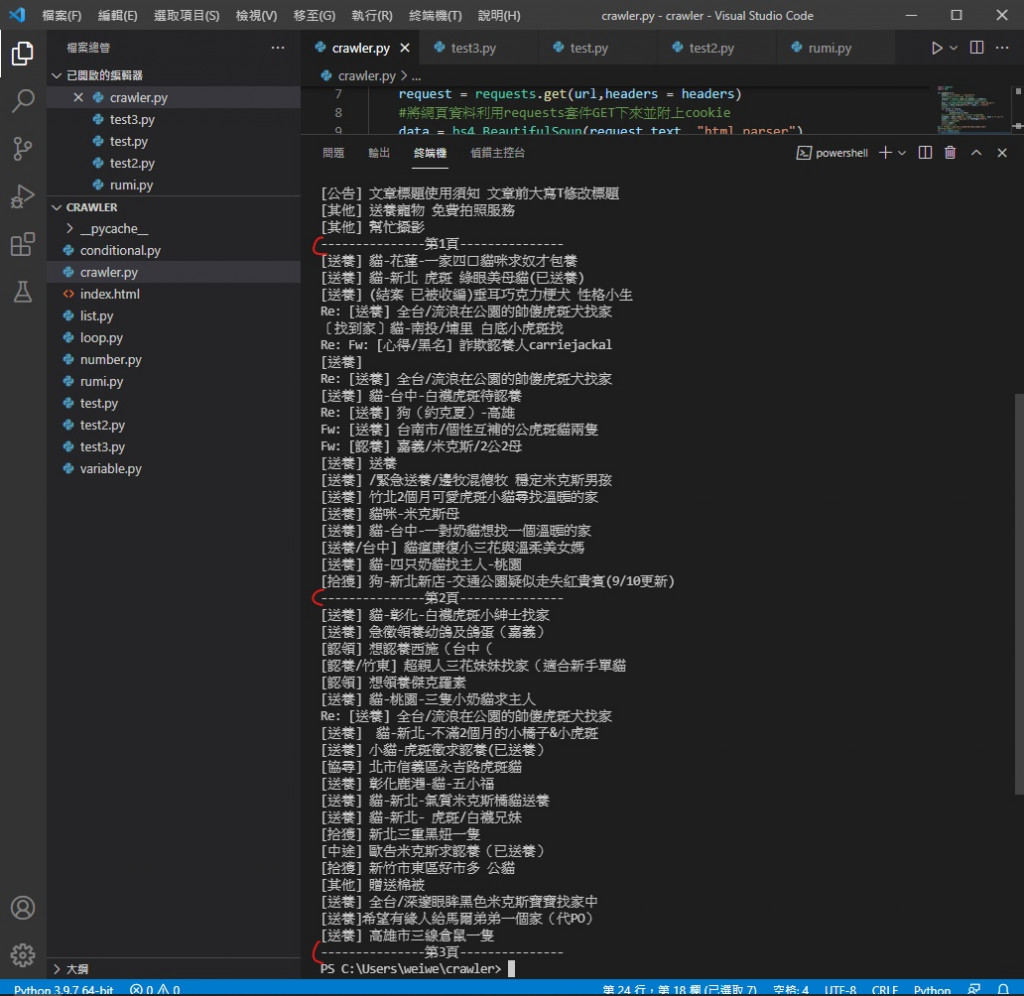
可以看到变得方便阅读许多
再来我们要领养动物总要在标题看到喜欢的动物後 能去网站看它可不可爱
所以我们要找到每篇文章的 url 在哪
一样打开网页 F12 记得点左上角用来找位置的小工具
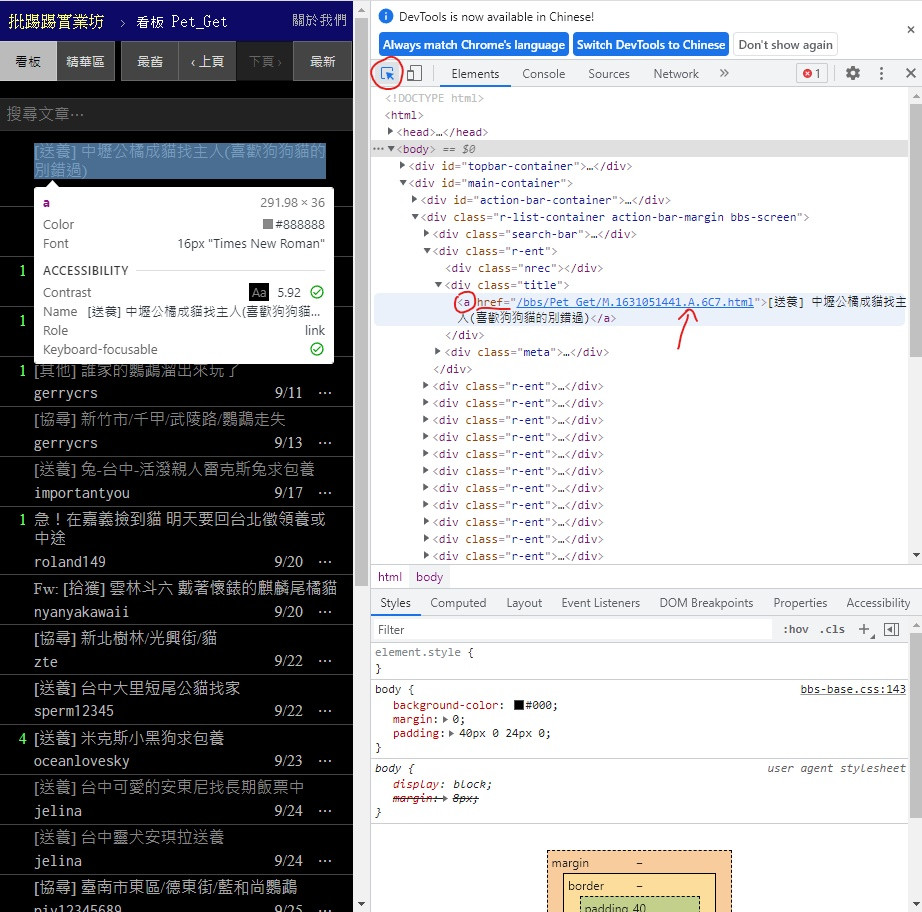
可以看到 在 < div > class = "title" 中的 < a > 标签内的 href 部分
这不就跟文章标题一样在 < a > 里面吗
所以不用再重新写一个部份给它 只需要把它加进去就好
所以把 getData( ) 内用来印出文章标题的 for 回圈内的 print 里改掉
从 print(title.a.text)
改成 print("https://www.ptt.cc"+title.a["href"],title.a.text)
注意 href 的呼叫格式比较特别
执行效果
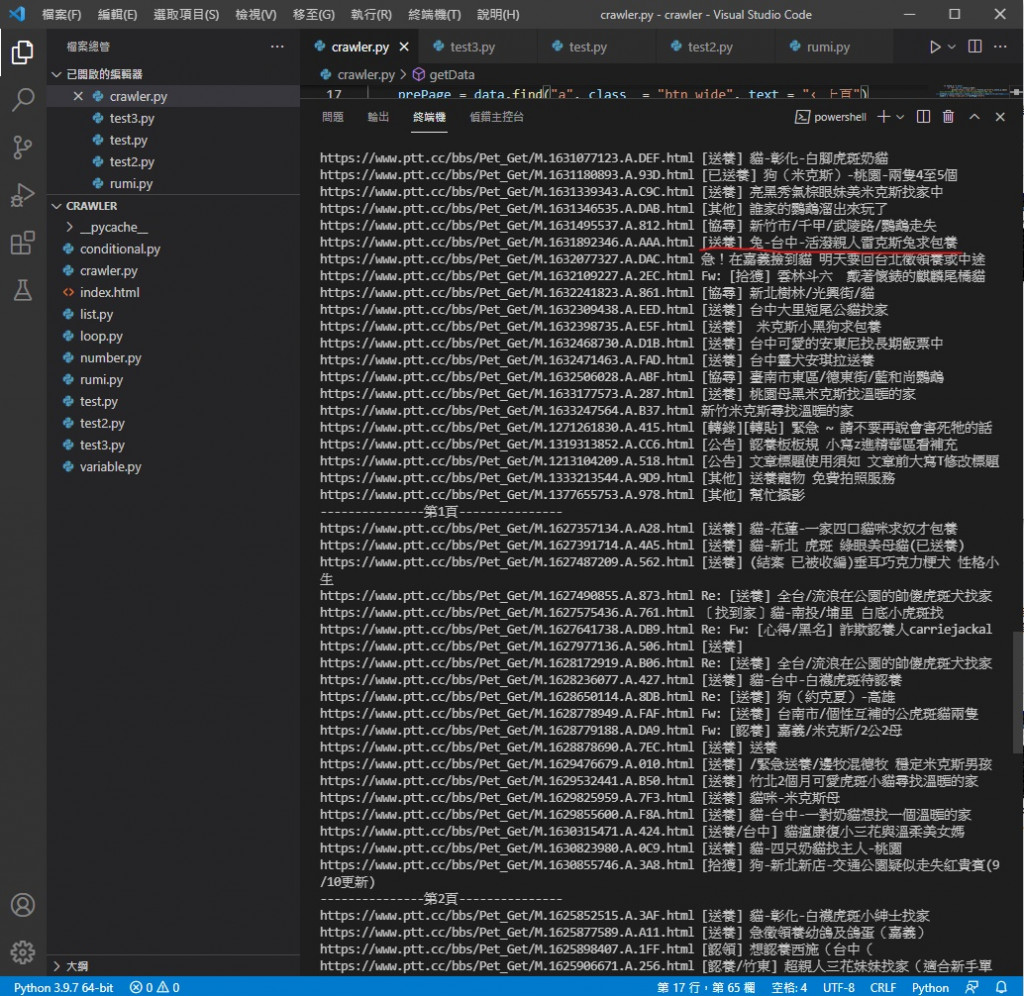
让印出的标题前面加上 该文章的网址
这样我们看到喜欢的就可以去网站看看牠的可爱模样跟领养资讯
最後 是增加筛选方法
假设你不喜欢兔兔 就在印出文章标题跟 url 的 for 回圈里多加一层 if
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
print("https://www.ptt.cc"+title.a["href"],title.a.text)
意思是如果 title.a.text 内没找到 "兔" 这个字元才执行里面的 print
执行效果
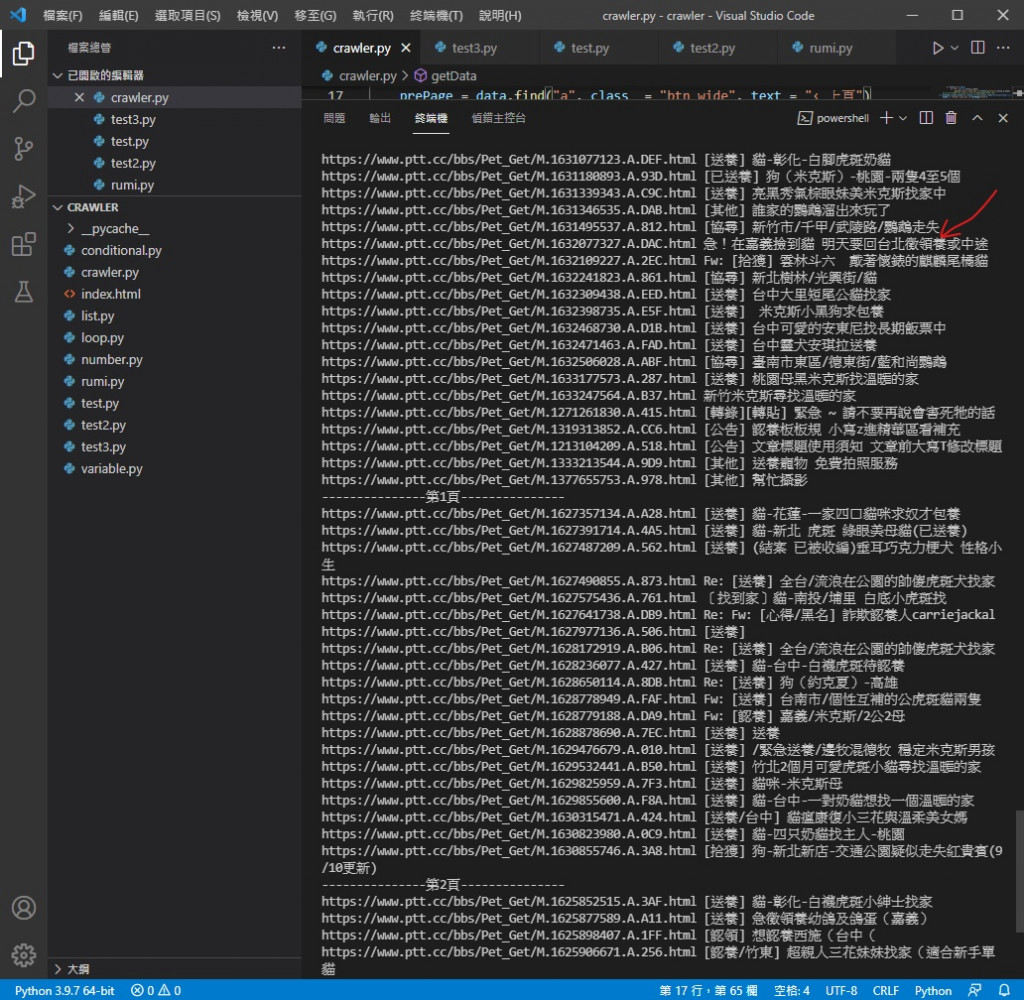
还记得上张图的画线位置吗
本来有兔兔相关的被筛选掉了
你可以用这个方法筛选掉不想养或不能养的
只要更改 if 的条件就好
今天的程序码
import requests
import bs4
def getData(url):
headers = {"cookie" : "over18=1"}
#建立headers用来放要附加的cookie
request = requests.get(url,headers = headers)
#将网页资料利用requests套件GET下来并附上cookie
data = bs4.BeautifulSoup(request.text, "html.parser")
titles = data.find_all("div", class_ = "title")
#解析网页原始码
for title in titles:
if title.a != None:
if "兔" not in title.a.text:
print("https://www.ptt.cc"+title.a["href"],title.a.text)
#利用for回圈印出全部并筛选掉已被删除的文章以及印出URL
prePage = data.find("a", class_ = "btn wide", text = "‹ 上页")
newUrl = "https://www.ptt.cc"+prePage["href"]
#抓取上页按钮内URL
return newUrl
#回传newUrl出去
url = "https://www.ptt.cc/bbs/Pet_Get/index.html"
#抓PTT领养版的网页原始码
for i in range(1,4,1):
url = getData(url)
print("---------------第"+str(i)+"页---------------")
#利用for回圈执行getData()函式3次
今天我们对程序进行了优化 明天我们要来介绍档案读写
早安闲聊区
你知道吗?
有鸟活了67岁喔
每日二选一
你比较喜欢远距还是实体上班上课呢
<<: 从零开始的8-bit迷宫探险【Level 29】让你的 App 与众不同!设计 Icon 及 LaunchScreen
>>: [Day 22] 卷积类明星模型大乱斗 ! EFN特别版
[Day 21] Facial Recognition: 只需要OpenCV就可以达成即时人脸辨识
昨天的内容还可以吸收吗? 也许有人会问: 这些神经网路模型还有GPU、CUDA什麽的我都不懂,能不能...
新零售行销模式案例,全通路时代来临该如何布局
新零售行销模式案例,全通路时代来临该如何布局,一直以来都在担任辅导顾问为中小企业解决网路行销问题但都...
DAY 13 资料库-建立并操作Heroku PostgreSQL
Heroku PostgreSQL是一种Heroku提供的PostgreSQL服务,可免费使用,免费...
9/29(三) 制造业资安趋势:永续营业风险大解密线上研讨会
制造业是台湾经济的生力军,疫情延烧并未影响营运,资安事件反而成为不定时炸弹,造成企业商誉甚或营收受损...
Day29- 这是替身攻击!! 替换你的pod Telepresence
在前面我们介绍到了各种建立以及产生pod的方式,但是当你已经建构好一个系统後,写好的程序要更新以及测...