Jupyter Notebook 输入栏位设计(1)
前言
撰写机器学习/深度学习相关程序时,我们常要调整超参数(Hyperparameters),观察模型的准确度或其他效能指标的变化,如果能设计各式输入栏位,就很容易说明 what-if 或将程序提供他人使用。
让我们搞定它吧
ipywidgets套件提供我们在 Jupyter Notebook 内设计各式输入栏位,安装指令如下:
pip install ipywidgets
之後启动 Jupyter Notebook 确定是否安装成功:
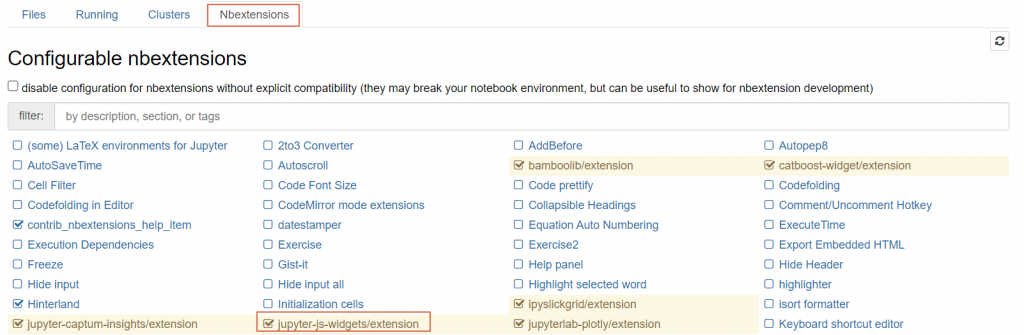
如果未现该扩充程序,执行以下指令,并确定有打勾:
jupyter nbextension enable --py widgetsnbextension
测试
- 本篇先介绍 interact 函数的用法。
# 载入套件
from ipywidgets import interact
# 定义一个简单函数
def f(x):
return x
# 呼叫 interact 函数,如 x 为整数则输入栏位为一拉杆(slider)
interact(f, x=10)
执行结果如下,拖曳拉杆,可改变输入值:

- 产生其他类型的输入栏位。
# 如 x 为boolean则输入栏位为 checkbox
interact(f, x=True)
# 如 x 为字串则输入栏位为文字框
interact(f, x='')
# 如 x 为list则输入栏位为下拉式栏位
interact(f, x=[1,2,3])
interact 会视 x 参数资料型态产生各式输入栏位。
- 直接使用装饰器(Decorator),不须呼叫interact函数。也可以同时可设定多个栏位。
# 使用装饰器(Decorator)
@interact(x=20, y=1.0)
def g(x, y):
return x + y
应用
虽然在画面上可以看到我们输入值,但没办法在下面的程序码抓到它,笔者一度脑筋打结,後来google一下,才了解必须要在函数中使用输入值,以下介绍两种应用。
- 筛选资料:指定鸢尾花(Iris)类别,筛选 Pandas Data Frame。
# 筛选资料
import pandas as pd
import numpy as np
from sklearn import datasets
@interact(x=[0,1,2])
def f(x):
# 载入鸢尾花资料
ds = datasets.load_iris()
df=pd.DataFrame(ds.data, columns=ds.feature_names)
df['y'] = ds.target
# 依据输入值筛选资料
return df.query(f'y == {x}')
执行结果如下,改变输入值可筛选资料:
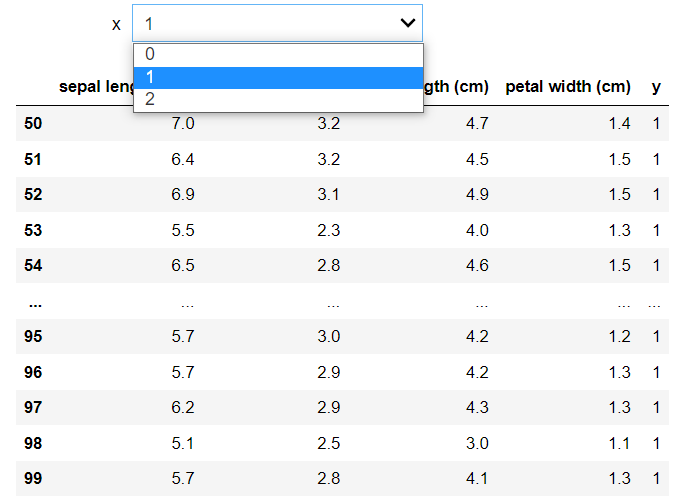
- 参数调校(tuning):以下利用 interact 指定参数值,进行参数调校,函数会传回准确度。
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
@interact(x=(3,11))
def f(x):
# 载入鸢尾花资料
ds = datasets.load_iris()
X=pd.DataFrame(ds.data, columns=ds.feature_names)
y=ds.target
# 切割训练及测试资料
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = .2)
# KNN 模型的 n_neighbors 参数调校
clf = KNeighborsClassifier(n_neighbors = x)
clf.fit(X_train, y_train)
return f'score={clf.score(X_test, y_test)}'

结语
够简单吧? 美中不足的是,没办法在函数外抓到输入值,还好有人解决这个问题,请待下回分解。
Core Web Vitals 的新指标 INP
在今年的 Google I/O 大会中,Google 介绍了一个名为 INP(Interaction...
Day14 - 动态 新增/删除 Collection 项目(二) - Html Helper
这篇调整的方向是 透过 Partial View 来 Render Collection 项目 透过...
【资料结构】树_实作-二元树的前中後追踪&&最大最小值&树叶
tree-二元树的前中後追踪&&最大最小值&树叶 实作练习 说明 实习课的一...
[Python]使用Pillow,将图片由RGB转灰阶(Grayscale)
RGB -> Gray scale Gray scale(灰阶影像) from PIL imp...
day 22 - NSQ Consumer & graceful shutdown
一个服务发出讯息之後, 可以由多个服务分别注册多个channel来监听, 同一个TOPIC底下的每个...