[Day 14] Audit perfomance — 模型也要期末稽核༼ಢ_ಢ༽
It is only our conception of time that makes us call the Last Judgement by this name. It is, in fact, a kind of martial law. — Franz Kafka
前言
在前面的文章中,我们一直围绕着建立模型的迭代实验过程进行讨论,也提到了一个能在产业环境表现良好的模型该达到什麽标准。
而当经过数次回圈得到不错的模型之後,其实还可以再做一次深度的错误分析来对系统进行最後评断以确保它的可行性:

*图片修改自 MLEP, Selecting and training a model — Key challenges
那在最终评断 (Final audit) 中还需要注意什麽呢?
让我们看看其中有什麽眉角吧!!
Audit performance
通常高阶指标 (Metric) 很容易把模型在某些特定资料上发生的问题隐藏起来,而对那些资料来说,不管高阶指标表现多好,得到的预测值都会是很差的。
如果将这个模型部署到产品端,使用者体验肯定也不会太好,因此在部署前最好再对模型表现进行一次深入的分析。
最终评断的流程如下 (检查准确度、公平性/偏见与其他问题):
-
集思广益找出系统可能出错的地方,例如检视:
- 在某些关键子集上的表现 (例如种族、性别)。
- 特定错误类型出现的频率 (例如 False Positive、False Nagative)。
- 在罕见类别的表现。
可以先从达成三个里程碑会遇到的问题开始检查 (参考 [Day 09] 建立机器学习模型 — Andrew Ng 大神说要这样做)。
但实际上会出现的错误依产业别会有很大的不同,特别是对於公平性与偏见的标准还很不一致,所以要将这两点考量铭记在心。
以语音辨识为例,可以检视:- 不同性别、种族的准确率。
- 不同装置的准确率。
- 转译成粗口的发生频率。
-
建立可以在这些错误发生时正确评判模型表现的指标,并施加在对应的资料子集上。
以语音辨识为例,可以建立以下指标:- 不同性别与主要口音的平均准确率。
- 不同装置的平均准确率。
- 输出中含有粗口的频率。
找出适当的指标之後,MLOps 工具可以帮助我们自动触发验证流程,例如 TensorFlow Model Analysis (TFMA) 就能在不同资料子集上详细计算各种指标。
-
说服老板这些问题很值得担心,以及这些指标可以用来解决问题。
TensorFlow Model Analysis
为了揪出被隐藏在高阶指标之下的问题,可以使用 TensorFlow Model Analysis (TFMA) 针对模型在不同资料切片上的表现进一步分析,其粗略架构如下图:
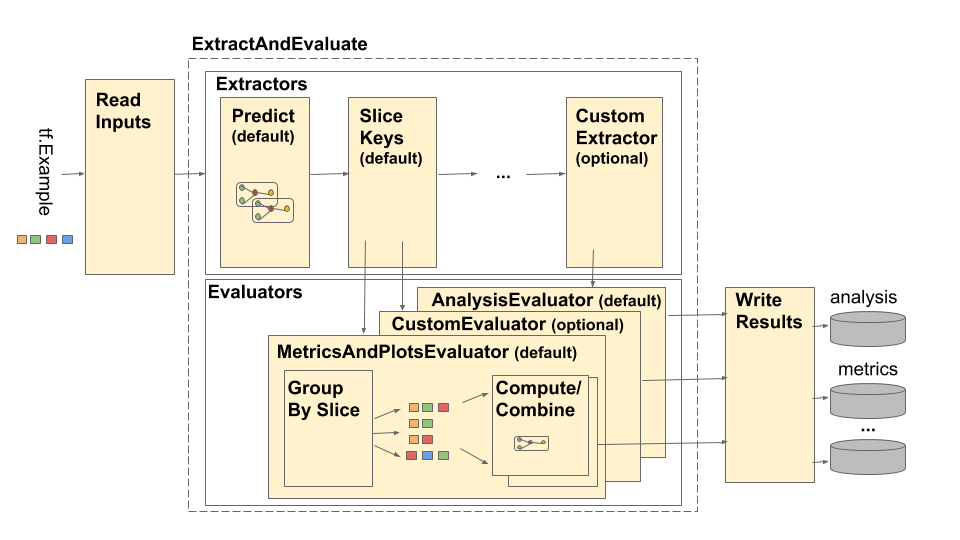
*图片来源:Tensorflow Model Analysis Architecture
TFMA Pipeline 由四个主要部件组合而成:
- Read Inputs — 将原始输入 (CSV、TFRecords 等) 转换成下一个阶段可以理解的字典格式
tfma.extracts。 - Extractors — 利用 Apache Beam 进行分散式处理,例如
SliceKeyExtractor将原始资料集拆分成不同切片以供PredictExtractor进行预测,其结果再次以tfma.extracts字典的形式传到下一个阶段。 - Evaluators — 同样利用 Apache Beam 进行分散式处理,例如
MetricsAndPlotsEvaluator会撷取所需的资料并搭配从前一阶段收到的预测值来评估模型表现,这步骤可以使用多种 Evaluator,甚至可以自创符合需求的 Evaluator。 - Write Results — 将结果写入硬碟中。
可以发现 TFMA 其实跟我们比较熟悉的 TensorBoard 功能有点像,两者都可以用来分析模型的表现,主要差别在於两者进行运算的对象与时间点不同,这会造成用途上的差别如下:
- During training vs after training
- One model vs multiple models over time
- Aggregate vs sliced metrics
- Streaming vs full-pass metrics
而各个不同处的详细解说请参考 Introducing TensorFlow Model Analysis,但从以下示意图就可以看出 TensorBoard 主要处理来自 checkpoints 的流动指标 (streaming metrics),而 TFMA 则专注於处理输出的 SavedModel:

*图片来源:Introducing TensorFlow Model Analysis
以上就是今天的内容啦,明天就是 Modeling 的最後一篇文章,要来讲实验管理,明天见罗。

参考资料
- Coursera — Introduction to Machine Learning in Production
- Introducing TensorFlow Model Analysis: Scaleable, Sliced, and Full-Pass Metrics
>>: Flutter基础介绍与实作-Day15 Onboarding、Login、Sign Up范例实作(2)
DAY3-JAVA的运算子和运算式
今天就来看看JAVA中的运算子和运算式吧! 这边就先简单介绍一下谁是运算元谁是运算子吧~ int b...
从零开始的8-bit迷宫探险【Level 29】让你的 App 与众不同!设计 Icon 及 LaunchScreen
回到村子後,山姆变成了斜杠青年,他将探险的故事写成了一本书。 书的封面印着山姆的肖像。 而书名就叫...
[Day12]- 函数设计
基本函数设计 函数基本定义,基本格式如下: def 函数名称 (参数1,参数2,….): 要执行的...
离职倒数6天:把事业分解成几个必然的选择题,是成功学的陷阱
今天跟朋友在讨论《过度努力》时,朋友说自己对「冒牌者效应」这个词的感觉很复杂 他觉得自己的确有这个词...
Day 11-Atlantis 做 Terraform Remote Plan & Remote Apply
使用 atlantis 做 terraform automation,Terraform Remot...