第一次的爬虫(2)
那我就延续上一篇的实作吧!
已经将会用到的套件装上,并且在网站的控制室找到所需的资讯位置,接下来就是撰写程序啦!
下面我先用express套件来简单架设服务器,以便我用来观看爬虫下来的结果。
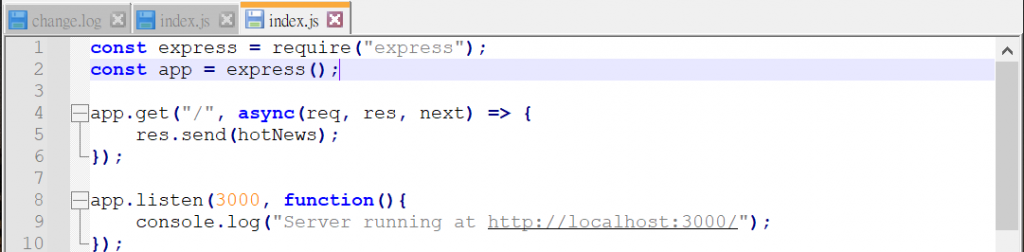
然後再利用superagent套件,用.get()的方法来访问指定页面,资料将会放在res中。

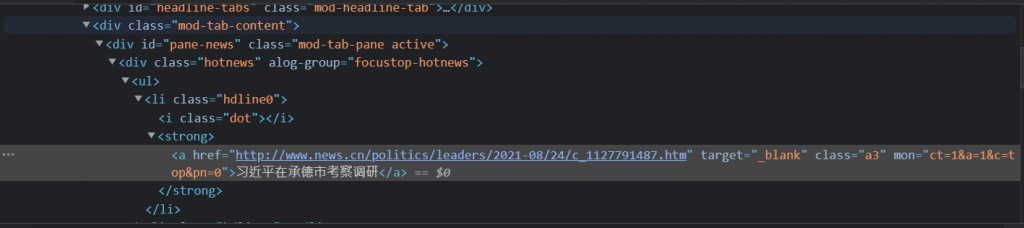
接下来就是用cheerio套件来获取所需要的资料,页面返回的资料会在res中,用.load()的方法去寻找指定id中的那些项目,比如说我是要找新闻标题,那标题的资讯在id = pane-news中下拉的…的项目中,就以下方程序码第27行为例,接下来就是标示出新闻标题以及连结,最後存放在hotNews矩阵中

下面就是服务器中跑出的结果
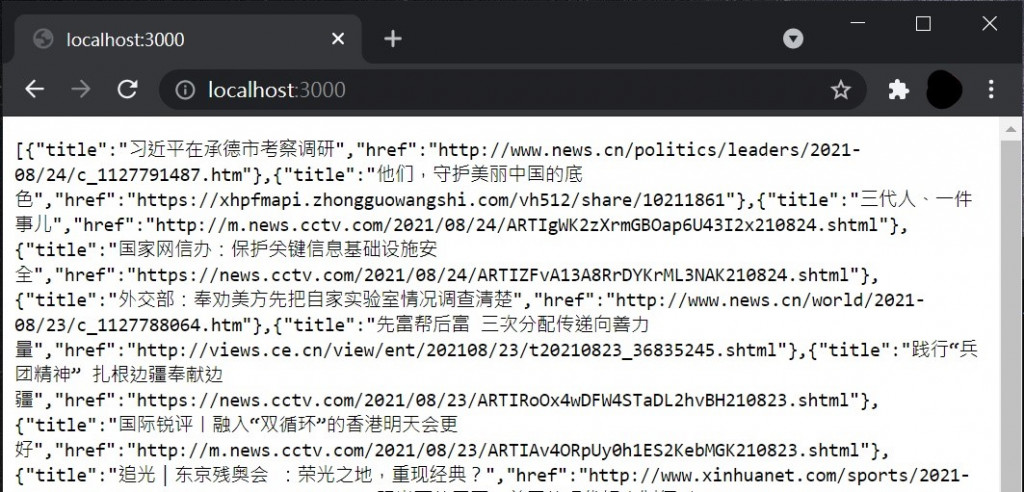
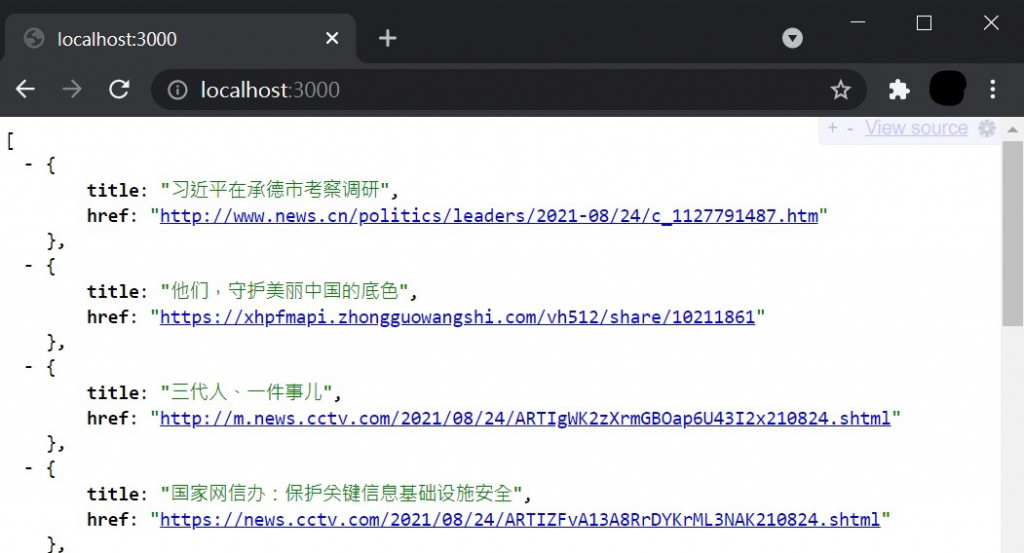
像上面那样很难看清楚所收集的资料有哪些,所以我在chrome加装了JSONView扩充功能,使结果能够更整齐
>>: [Day 4] 使用 Gradle Multi-Project Builds X Shadow Plugin X Docker Compose 建置、打包、部署
Day17边框(CSS)
Border 边框样式 今天来介绍个基本的边框 <p class="solid &q...
开放最短路径优先 (OSPF)
-动态路由(来源:Wayne Hickey) OSPF 可以作为路由器的一个组成部分运行;它还可以...
06 - TPM - Tmux Plugin Manager 与它的插件
使用 Tmux 的插件管理工具来载入各式插件,可以为使用者减少配置的麻烦。如果不使用插件,使用者必须...
28. 解释 CSS Box Model ( box-sizing )
今天也是复习CSS,是非常之基础的box-sizing。 Box Model 前一篇文提到,HTML...
Unity自主学习(十二):认识Unity介面(3)
接续昨天的进度,今天则是研究了"阶层管理区"主要的功能,及操作方式。 阶层管理区...