[Day 17] 轻量化的梯度提升机 - LightGBM
LightGBM
今日学习目标
- LightGBM 与 XGBoost 比较
- 了解 LightGBM 优点
- 实作 LightGBM 处理资料不平衡资料
- 信用卡盗刷侦测 (二元分类)
前言
LightGBM 是属於 GDBT 家族中成员之一,相较於先前介绍的 XGBoost 两者可以拿来做比较。简单来说从 LightGBM 名字上观察,我们可以看出它是轻量化 (Light) 的梯度提升机 (GBM) 的实例。其相对 XGBoost 来说它具有训练速度快、记忆体占用低的特点,因此近几年 LightGBM 在 Kaggle 上也算是热门模型一。

LightGBM 与 XGBoost 比较
这两种演算法都使用贪婪的方法来最小化损失函数的梯度来构建所有的弱学习器。其 tree-based 演算法所面临的挑战是如何挑选最佳的叶节点的切割方式,然而 LightGBM 和 XGBoost 分别使用不同的优化技术与方法来识别最佳的分割点。
LightGBM 优点
LightGBM 由微软团队於 2017 年所发表的论文 LightGBM: A Highly Efficient Gradient Boosting Decision Tree 被提出。其主要想法是利用决策树为基底的弱学习器,不断地迭代训练并取得最佳的模型。同时该演算法进行了优化使得训练速度变快,并且有效降被消耗的资源。LightGBM 也是个开源专案大家可以在 GitHub 上可以取得相关资讯。
在官方的文件中也条列了几个 LightGBM 的优点:
- 更快的训练速度和更高的效率
- 低记忆体使用率
- 更好的准确度
- 支援 GPU 平行运算
- 能够处理大规模数据
LightGBM 使用 leaf-wise tree 演算法,因此在迭代过程中能更快地收敛。但是 leaf-wise tree 方法较容易过拟合。详细的内容可以参考文章最後提供的相关资源。
处理 unbalance 资料
在使用 LightGBM 做分类器时该如何处理样本类别分布不平衡的问题?一个简单的方法是设定 is_unbalance=True,或是 scale_pos_weight 注意这两个参数只能择一使用。以下我们就使用一个不平衡的资料集,信用卡盗刷预测来做示范。首先我们可以载入 Google 所提供的信用卡盗刷资料集,详细资讯可以参考这里。
import pandas as pd
raw_df = pd.read_csv('https://storage.googleapis.com/download.tensorflow.org/data/creditcard.csv')
X=raw_df.drop(columns = ['Class'])
y=raw_df['Class']
print('X:', X.shape)
print('Y:', y.shape)
载入成功後我们可以看到该资料集共有 284807 笔资料,每一笔资料有 30 个特徵。
X: (284807, 30)
Y: (284807,)
为了方便检视实验结果,我们依照 y 的比例进行训练集与测试集的切割。这里值得一提的是,stratify 为分层随机抽样。特别是在原始数据中样本标签分布不均衡时非常有用,一些分类问题可能会在目标类的分布中表现出很大的不平衡时例如:负样本可能比正样本多几倍。在这种情况下,建议使用分层抽样。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
print('X_train:', X_train.shape)
print('X_test:', X_test.shape)
输出结果:
X_train: (199364, 30)
X_test: (85443, 30)
训练集与测试集经由 7:3 的比例下去随机切割资料。我们可以透过 Pandas 做更近一步的分析,可以发现切割出来的训练集与测试集在盗刷(1)与非盗刷(0)的资料比例是差不多的。
接下来重头戏出场。我们采用 LightGBM 分类器,若还没安装的读者可以参考以下指令进行安装。
pip install lightgbm
安装结束後即可载入 lightgbm 套件并选用 LGBMClassifier 分类器。另外我们可以在建立分类器同时设定模型超参数,这里我们来示范使用 is_unbalance=True 训练模型。除此之外模型的超参数有很多,可以由官方文件中查阅。以下帮各位整理常用的方法:
Parameters:
- num_iterations: 总共迭代的次数,即决策树的个数。预设值为100。
- learning_rate: 学习速率,预设0.1。
- boosting: 选择 boosting 种类。共四种 gbdt、rf、dart、goss,预设为 gbdt。
- max_depth: 树的最大深度,预设值为-1即表示无限制。
- min_data_in_leaf: 一个子叶中最少数据,可用於处理过拟合。预设20笔。
- max_bin: 将特徵值放入桶中的最大bins数。预设为255。
Attributes:
- feature_importances_: 查询模型特徵的重要程度。
Methods:
- fit: 放入X、y进行模型拟合。
- predict: 预测并回传预测类别。
- score: 预测成功的比例。
- predict_proba: 预测每个类别的机率值。
import lightgbm as lgb
model = lgb.LGBMClassifier(is_unbalance=True)
model.fit(X_train,y_train)
训练结束後即可使用刚切割好的测试集进行模型评估。我们可以发现准确率高达 94%。
from sklearn.metrics import accuracy_score
pred=model.predict(X_test)
print("Accuracy:", accuracy_score(y_test, pred))
输出结果:
Accuracy: 0.9401706400758401
如果要判断分类器的好坏,仅使用准确率来评估是一个不好的习惯。我们应该善用混淆矩阵做更近一步的分析,并查看正样本与负样本在预测上的表现。首先我们先来写一个计算混淆矩阵的函式,并用 seaborn 绘制出热力图矩阵。
import seaborn as sns
import matplotlib.pyplot as plt
def plot_confusion_matrix(actual_val, pred_val, title=None):
confusion_matrix = pd.crosstab(actual_val, pred_val,
rownames=['Actual'],
colnames=['Predicted'])
plot = sns.heatmap(confusion_matrix, annot=True, fmt=',.0f')
if title is None:
pass
else:
plot.set_title(title)
plt.show()
在评估模型之前我们先来查看测试集输出 y 的分布各是多少。透过 numpy 的 unique 方法可以计算 y_test 中每个类别的数量。从输出结果可以得知,85443 笔测试集中共有 85295 笔是标签 0(未盗刷)、148 笔是标签 1(盗刷)。知道这些真实数据的数量後,接下来我们就可以透过混淆矩阵来查看模型是否有将这些盗刷的资料被正确预测出来。
import numpy as np
unique, counts = np.unique(y_test, return_counts=True)
dict(zip(unique, counts))
输出结果:
{0: 85295, 1: 148}
plot_confusion_matrix 函式建立完成後即可呼叫。此函式有三个输入,分别为 y_test 实际输出答案、 pred 模型预测结果、title 图表标题(预设None)。相对应的变数输入後即可得到计算好的混淆矩阵。
plot_confusion_matrix(y_test, pred)
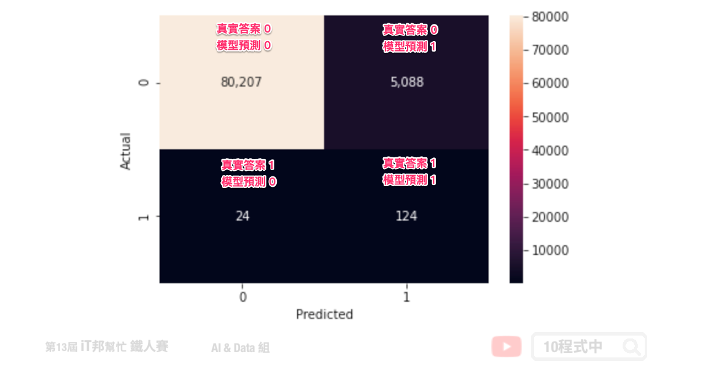
下图为实际 is_unbalance=True 的训练结果。我们可以发现在测试集中有 148 笔盗刷资料,其中有 124 笔盗刷被成功辨识出来。另外我们可以发现真实答案是没盗刷的资料居然有 5088 笔被误判成盗刷。
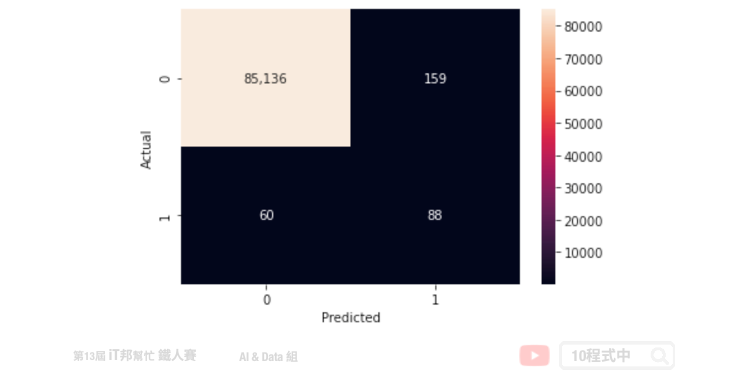
我们再来试试将 is_unbalance 设为 False 并观察混淆矩阵。可以发现虽然误判的数量减少了,但是真实答案中有 148 笔盗刷资料仅有 88 笔被成功辨识出来。我们可以猜想模型在大多数状况都会预测资料未被盗刷的机率较大。
Reference
本系列教学内容及范例程序都可以从我的 GitHub 取得!
<<: 大共享时代系列_013_网页浏览器(web browser)
[第十三天]从0开始的UnityAR手机游戏开发-如何在辨识图卡时拨放影片02
今天继续上一章节的制作 在Hierarchy点击右键新增Video→Video Player 点击V...
Day-7:Rails Turbolinks
月圆之日, 瓦力在这边祝大家中秋佳节愉快!! 虽然我仍在专案水深火热写扣!! 闻夯骂乓~写扣中!你说...
Day 19 : 案例分享(6.2) 人事、差勤与薪资 - 组织架构、人事资料及个人合同管理
案例说明及适用场景 组织架构是由部门及职务做为骨架,员工就职於某一个职务 员工在企业的职务,就如同系...
从国家标准技术研究院(NIST)的角度来看,满足最低安全要求的控制基准的最佳来源-准则(Guidelines)
NIST SP 800-53 R4是一个指南,在附录D 安全控制基线–摘要中提供了安全控制基线。它还...
Day43. 蝇量模式
本文同步更新於blog Flyweight Pattern 又称为享元模式,於相似物件中共享尽可能...